الضبط الدقيق مقابل RAG: أي النهجين يُثبت فعاليته حقاً في الذكاء الاصطناعي للمؤسسات عام 2026
RAG تنتصر في معظم معارك المؤسسات — لكن Fine-tuning لا يزال لها دورها
في الغالبية العظمى من حالات استخدام الذكاء الاصطناعي في المؤسسات خلال عام 2026، يُحقق RAG (التوليد المُعزَّز بالاسترجاع) عائد استثمار أفضل من fine-tuning النموذج الأساسي. هذه ليست خطة تسويقية من بائع — بل هي الاستنتاج الذي تصل إليه عندما تنظر إلى التكلفة الإجمالية للملكية، وتأخير التحديث، ومعايير الدقة عبر عمليات النشر الفعلية. تظل Fine-tuning الخيار الصحيح في مجموعة ضيقة لكنها مهمة من السيناريوهات: التكيف مع مجالات متخصصة للغاية، والاستدلال على الحواف مع قيود زمنية، ومهام تناسق الأسلوب/التنسيق حيث لا يُقبل أي استرجاع خارجي.
يحلل هذا المنشور بالتفصيل لماذا، مع الأرقام. إذا كنت مهندس ذكاء اصطناعي تختار بين الطريقتين لقاعدة معرفة داخلية، أو مساعد موجه للعملاء، أو مصنف متخصص في مجال معين، فهذا هو الإطار الذي سيوفر لك شهوراً من التكرار المكلف.
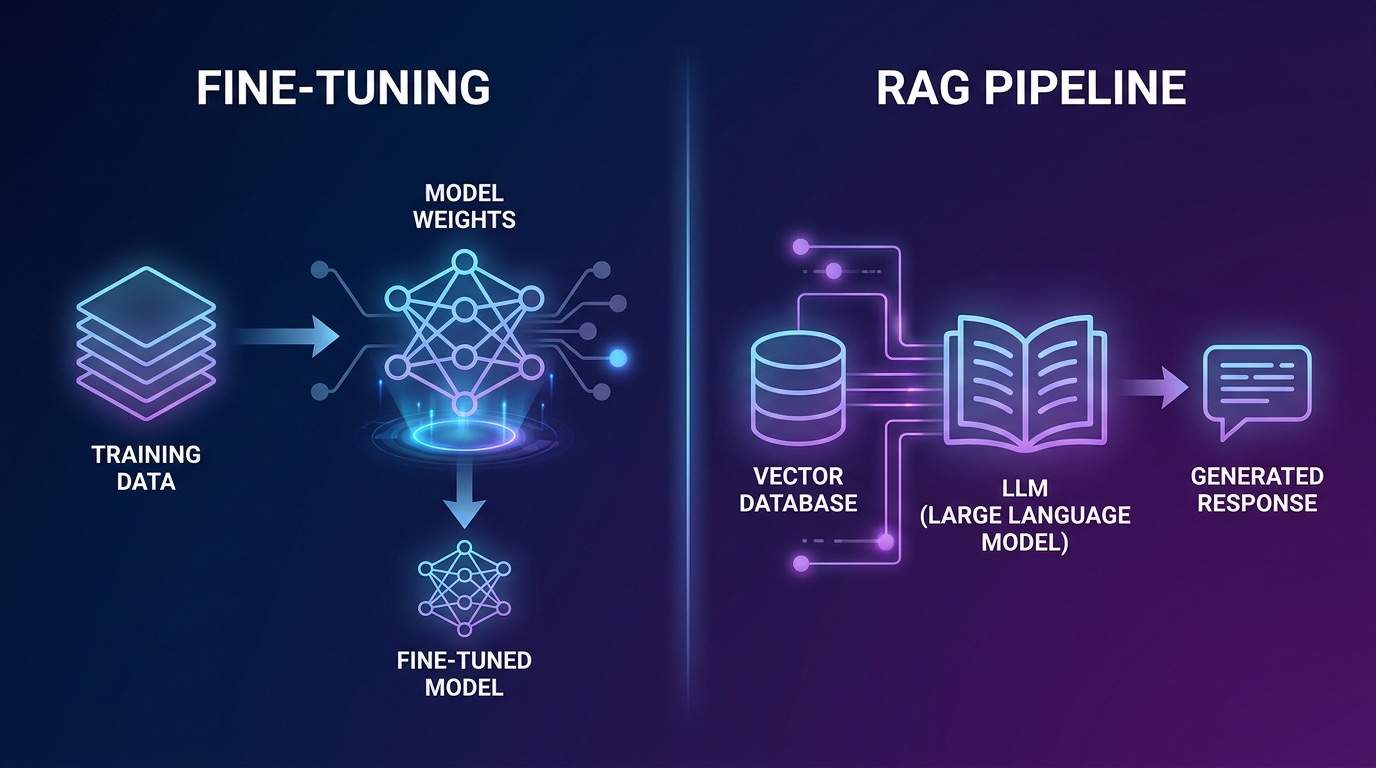
ما يفعله كل نهج فعلياً (أبعد من الأساسيات)
أنت تعرف التعريفات النظرية. ما يهم عملياً هو فهم أنماط الفشل لكل منهما.
Fine-tuning في الإنتاج
تُعدل Fine-tuning أوزان النموذج باستخدام مجموعة بيانات منسقة من أزواج (المطالبة، الإكمال). النتيجة هي نموذج استوعب الأنماط والمصطلحات والسلوك من بيانات التدريب في معاملاته. العرض التقديمي الكلاسيكي للمؤسسات: نموذج واحد مُعدَّل fine-tuning، بدون حمل استرجاع زائد، واستدلال سريع.
التكاليف الخفية: تشغيل fine-tuning على نموذج من 7 مليارات معلمة باستخدام QLoRA على بطاقة A100 سعة 80 جيجابايت يستغرق من 4 إلى 12 ساعة ويكلف تقريباً 40 إلى 120 دولارًا على أسعار GPU السحابية اعتبارًا من الربع الأول من عام 2026. بالنسبة لنموذج من 70 مليار معلمة، اضرب في 8 إلى 10 مرات. هذا مجرد التشغيل الأول. في كل مرة تتغير فيها قاعدة معرفتك — تحديث منتج، مراجعة سياسة، لائحة جديدة — إما أن تعيد التدريب أو تقبل بسلوك نموذج قديم. معظم مجالات المعرفة في المؤسسات تتغير أسبوعياً أو يومياً.
تدهور الدقة هو الفخ الآخر. يمكن للنموذج المُعدَّل fine-tuning أن يهلوس بثقة بمعلومات من توزيع التدريب الخاص به أصبحت الآن قديمة. وجد تحليل داخلي من Morgan Stanley لنموذجهم التجريبي للمساعد الذكي (تم الكشف عنه في مكالمة أرباح عام 2025) أن النماذج المُعدَّلة fine-tuning على البيانات المالية تطلبت إعادة تدريب كاملة كل 6 إلى 8 أسابيع للحفاظ على دقة مقبولة في ظروف السوق الحالية، بتكلفة تزيد عن 200,000 دولار لكل ربع سنة في حسابات GPU وحدها.
RAG في الإنتاج
يستعيد خط أنابيب RAG أجزاء المستندات ذات الصلة من مخزن المتجهات في وقت الاستدلال ويحقنها في نافذة السياق للنموذج. يستنتج النموذج بناءً على الأدلة المستردة بدلاً من الاعتماد فقط على الأوزان المُدرَّبة.
المزايا الرئيسية هي الحداثة وقابلية التدقيق. عندما تتغير قاعدة معرفتك، تقوم بتحديث فهرس المتجهات — وهي عملية تستغرق دقائق للتحديثات المتزايدة وساعات لإعادة الفهرسة الكاملة. لا حاجة لإعادة تدريب النموذج. كما تحصل على إسناد المصدر: يمكن لكل إجابة الاستشهاد بجزء المستند الدقيق الذي استندت إليه، وهذا مهم جداً للصناعات الخاضعة للتنظيم.
أنماط الفشل الحقيقية: جودة الاسترجاع هي عنق الزجاجة. بحث تشابه جيب التمام الساذج عبر التضمينات يستعيد المحتوى التقريبي الصحيح لكنه يفقد سلاسل الاستدلال متعددة الخطوات الدقيقة. أنظمة RAG الإنتاجية في شركات مثل Salesforce و ServiceNow انتقلت إلى الاسترجاع الهجين (كثيف + sparse BM25) بالإضافة إلى إعادة الترتيب باستخدام cross-encoder، مما يضيف حوالي 80-120 مللي ثانية من زمن الوصول لكل استعلام ولكنه يحسن دقة الإجابة بنسبة 15-25% على المعايير الداخلية.
مواجهة مباشرة: التكلفة، زمن الوصول، الدقة
التكلفة الإجمالية للملكية (سنوياً، مؤسسة متوسطة الحجم)
افترض 10 ملايين استعلام/سنة، وقاعدة معرفة من 50,000 وثيقة تُحدَّث أسبوعياً، ونموذج من فئة GPT-4o.
- نهج Fine-tuning: fine-tuning أولي (800-2,000 دولار) + إعادة تدريب أسبوعية (400-1,200 دولار/أسبوع) + استضافة النموذج المُعدَّل fine-tuning للاستدلال (3,000-6,000 دولار/شهر) = 85,000-140,000 دولار/السنة
- نهج RAG: استضافة قاعدة بيانات المتجهات (Pinecone أو Weaviate أو pgvector على RDS) (200-800 دولار/شهر) + توليد التضمينات للتحديثات الأسبوعية (50-200 دولار/شهر) + استدلال النموذج الأساسي (4,000-8,000 دولار/شهر) = 52,000-108,000 دولار/السنة
RAG أرخص بنسبة 20-40% على هذا النطاق. تتسع الفجوة بشكل كبير عندما يزداد تكرار تحديث المعرفة.
زمن الوصول
- نموذج مُعدَّل fine-tuning (بدون استرجاع): 200-400 مللي ثانية p95 لاستجابة من 500 رمز على نقطة نهاية GPU مخصصة
- خط أنابيب RAG (تضمين + بحث متجه + LLM): 400-900 مللي ثانية p95 اعتماداً على تعقيد الاسترجاع وإعادة الترتيب
- نموذج مُعدَّل fine-tuning + RAG (هجين): 500-1,100 مللي ثانية p95
تتفوق Fine-tuning في زمن الوصول الخام بمقدار 200-500 مللي ثانية. بالنسبة لمعظم تطبيقات المؤسسات — المساعدات الداخلية، البحث في الوثائق، دعم العملاء — هذا الفرق غير محسوس للمستخدمين. إنه مهم للتطبيقات في الوقت الفعلي مثل واجهات الصوت (حيث يكون أقل من 500 مللي ثانية مطلباً صارماً) أو أنظمة التداول حيث للميلي ثانية قيمة دولارية مباشرة.
الدقة في المهام كثيفة المعرفة
على معيار FRAMES (مجموعة تقييم للأسئلة والأجوبة متعددة المستندات أصبحت المعيار الفعلي لتقييم RAG في عام 2025)، حقق خط أنابيب RAG مضبوط جيداً باستخدام GPT-4o دقة 72-78% على أسئلة متعددة الخطوات بأسلوب المؤسسات. سجل نموذج GPT-4o مُعدَّل fine-tuning في نفس المجال 61-67% — أقل، لأن النموذج المُعدَّل fine-tuning كان يجيب من أنماط محفوظة بدلاً من الأدلة المستردة، وتضمنت مجموعة الاختبار أسئلة حول معلومات تغيرت بعد تاريخ قطع التدريب.
بالنسبة لمهام التصنيف والاستخراج ذات المخططات الثابتة، تتفوق Fine-tuning: حقق نموذج Llama 3.1 8B مُعدَّل fine-tuning لاستخراج البيانات المنظمة دقة على مستوى الحقل بنسبة 94% مقابل 87% لنموذج GPT-4o مع سياق RAG، وبتكلفة استدلال تبلغ 1/8.
متى تكون Fine-tuning هي الخيار الصحيح فعلياً
هناك أربعة سيناريوهات حيث تتفوق Fine-tuning على RAG وتكون المقايضات مبررة:
1. المفردات والاستدلال في المجالات المتخصصة
إنشاء تقارير التصوير الطبي، تصنيف بنود العقود القانونية، التحقق من تصميم الرقائق — مجالات تكون فيها المصطلحات وأنماط الاستدلال وتنسيقات المخرجات متخصصة لدرجة أن النموذج الأساسي يحتاج إلى مئات الرموز من الشرح داخل السياق في كل استعلام. تعمل Fine-tuning على توزيع تكلفة هذا السياق عبر جميع الاستدلالات. يعتمد نموذج التلخيص السريري من Hippocratic AI ونظام تحليل العقود من Harvey AI على Fine-tuning تحديداً لأن مجالاتهم تتطلب أنماط استدلال لا يمكن استنباطها بشكل موثوق من خلال المطالبة وحدها.
2. متطلبات زمن الوصول الصارمة (أقل من 300 مللي ثانية)
واجهات الصوت، المساعدات البرمجية في الوقت الفعلي المدمجة في IDEs (مثل الإكمال التلقائي من Cursor)، والذكاء الاصطناعي على الحافة (on-device edge AI) حيث لا تتوفر بنية تحتية للاسترجاع. نموذج مُعدَّل fine-tuning بحجم 3-7 مليارات معلمة يعمل محلياً هو البنية القابلة للتطبيق الوحيدة عندما تحتاج إلى استجابة أقل من 300 مللي ثانية بدون رحلة شبكة ذهاباً وإياباً.
3. تنسيق وأسلوب مخرجات متناسقين
إذا كان تطبيقك يُنشئ مخرجات بتنسيق محدد للغاية — JSON منظم بمخطط مملوك، أسلوب كتابة دقيق لعلامة تجارية، طريقة تعبير بلغة برمجة معينة — فإن Fine-tuning تثبت هذا التنسيق بشكل أكثر موثوقية من هندسة المطالبات. تستخدم أدوات إكمال الكود مثل Copilot من GitHub و JetBrains Fine-tuning لهذا السبب.
4. لا يمكن للبيانات مغادرة بيئتك
بعض المؤسسات لا تستطيع إرسال المستندات إلى قاعدة بيانات متجهات خارجية أو واجهة برمجة تطبيقات LLM بسبب لوائح سيادة البيانات (متطلبات معالجة البيانات في المادة 28 من قانون الذكاء الاصطناعي الأوروبي، HIPAA، FedRAMP). نموذج مُعدَّل fine-tuning بالكامل محلياً بدون اعتماد على الاسترجاع هو أبسط من الناحية المعمارية من مجموعة RAG المحلية، على الرغم من أن الأخير أصبح قابلاً للتطبيق بشكل متزايد مع مجموعات Weaviate أو Qdrant المستضافة ذاتياً.
متى يكون RAG هو الخيار الصحيح (في معظم الأحيان)
RAG هو الخيار الافتراضي الصحيح لنشر المؤسسات عندما:
- تتغير قاعدة معرفتك أكثر من مرة كل ربع سنة
- تحتاج إلى إسناد المصدر للامتثال أو ثقة المستخدم
- توزيع استعلاماتك واسع (الأسئلة تغطي مواضيع كثيرة، وليس مجالاً ضيقاً)
- تعمل مع قاعدة معرفة أكبر من 10,000 وثيقة، حيث يصبح حفظ Fine-tuning غير موثوق
- تريد اختبار ترقيات النموذج بطريقة A/B بدون إعادة صياغة خطوط الأنابيب
مساعد Rovo من Atlassian، و Notion AI، ومنتج Fin من Intercom جميعها تستخدم بنى تعتمد على RAG أولاً. الخيط المشترك: قواعد المعرفة الخاصة بهم (صفحات Confluence، وثائق Notion، تذاكر دعم العملاء) تتغير باستمرار، والحداثة أمر غير قابل للتفاوض.
البنية الهجينة: أين يتجه الإنتاج
أكثر أنظمة الذكاء الاصطناعي للمؤسسات قدرة في عام 2026 تستخدم Fine-tuning و RAG معاً، ولكن بطريقة محددة. يتم تعديل الـ LLM الأساسي عن طريق fine-tuning على تنسيق المهمة وأسلوب الاستدلال — وليس على المعرفة الواقعية. المعرفة الواقعية تعيش بالكامل في طبقة الاسترجاع. يُطلق على هذا الفصل بين الاهتمامات أحياناً اسم "تنسيق fine-tuning + معرفة RAG."
نموذج Command R+ للمؤسسات من Cohere مبني على هذا المبدأ: تم تدريب النموذج (instruction-tuned) لاستدلال خاص بـ RAG (تأريخ الاستشهادات، تجميع الأدلة، سلسلة الأفكار متعددة الخطوات) بدلاً من الحقائق المجالية. يقوم العملاء بتوصيل قواعد المعرفة الخاصة بهم. النتيجة: استخدام أفضل للاسترجاع من النموذج الأساسي العام، بدون عبء إعادة التدريب لـ fine-tuning المعرفي.
إطار القرار: مخطط انسيابي عملي
أجب على هذه الأسئلة بالترتيب:
- هل تتغير قاعدة معرفتك أكثر من مرة كل ربع سنة؟ نعم ← RAG. لا ← تابع.
- هل تحتاج إلى إسناد المصدر أو مسارات التدقيق؟ نعم ← RAG. لا ← تابع.
- هل زمن الوصول p95 مطلب صارم أقل من 300 مللي ثانية؟ نعم ← Fine-tuning. لا ← تابع.
- هل مجالك متخصص لدرجة أن النموذج الأساسي يحتاج إلى مطالبات نظام من 500+ رمز للتصرف بشكل صحيح؟ نعم ← Fine-tuning (أو هجين). لا ← RAG.
- هل تمنع قواعد سيادة البيانات استدعاءات واجهات برمجة التطبيقات الخارجية؟ نعم ← قيّم RAG المحلي مقابل النموذج المحلي المُعدَّل fine-tuning بناءً على تعقيد البنية التحتية. لا ← RAG.
نقاط عملية قابلة للتنفيذ
- ابدأ بـ RAG. الاستثمار في البنية التحتية أقل، والتكرار أسرع، ويمكنك دائماً إضافة fine-tuning لاحقاً لمكونات محددة. العكس — التراجع عن استثمار في Fine-tuning — مكلف.
- إذا قمت بـ fine-tuning، فقم بذلك من أجل السلوك وليس الحقائق. تدرب على أنماط الاستدلال، وتنسيق المخرجات، وهيكل المهمة. احتفظ بالحقائق في طبقة الاسترجاع.
- استثمر في جودة الاسترجاع قبل التوسع. لم يعد الاسترجاع الهجين BM25 + الكثيف مع cross-encoder reranker مجرد خيار للإنتاج؛ إنه الأساس. RAG الذي يعتمد على تشابه جيب التمام الرخيص سيكون أداؤه أقل من نموذج أساسي بمطالبات جيدة.
- قس الحداثة بشكل منفصل عن الدقة. يمكن لنموذج أن يسجل درجات جيدة على معيار ثابت بينما يقدم إجابات قديمة في الإنتاج. أنشئ مجموعات تقييم من المستندات المضافة بعد تاريخ قطع التدريب الخاص بك.
- للحواف/الأجهزة: استخدم نماذج مُعدَّلة fine-tuning ومكمّمة (GGUF Q4_K