Fine-tuning vs. RAG: Welcher Ansatz funktioniert 2026 tatsächlich für Enterprise-AI
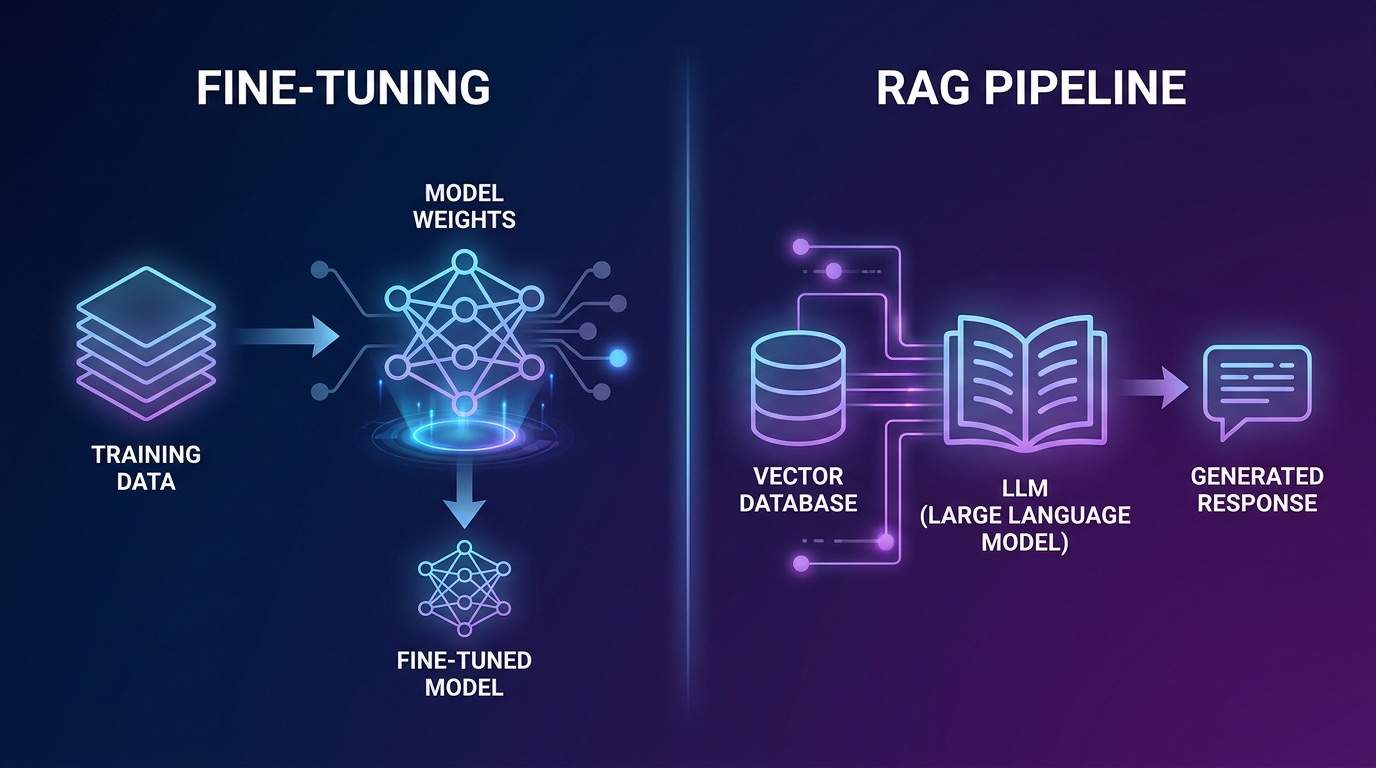
RAG gewinnt die meisten Enterprise-Schlachten – aber Fine-Tuning hat weiterhin seine Daseinsberechtigung
Für die überwältigende Mehrheit der Enterprise-KI-Anwendungsfälle im Jahr 2026 liefert Retrieval-Augmented Generation (RAG) eine bessere Rendite als das Fine-Tuning eines Basismodells. Das ist kein Verkaufsargument – es ist die Schlussfolgerung, zu der man kommt, wenn man die Gesamtbetriebskosten, die Aktualisierungslatenz und die Genauigkeits-Benchmarks über reale Bereitstellungen hinweg betrachtet. Fine-Tuning bleibt in einem engen, aber wichtigen Bereich von Szenarien die richtige Wahl: hochspezialisierte Domänenanpassung, latenzkritische Edge-Inferenz sowie Aufgaben zur Format-/Stilkonsistenz, bei denen kein externer Retrieval akzeptabel ist.
Dieser Beitrag erläutert genau, warum, und zwar mit Zahlen. Wenn Sie als KI-Ingenieur zwischen den beiden Ansätzen für eine interne Wissensdatenbank, einen kundenorientierten Copiloten oder einen domänenspezifischen Klassifikator entscheiden, finden Sie hier das Framework, das Ihnen Monate teurer Iterationen ersparen wird.
Was jeder Ansatz tatsächlich bewirkt (über die Grundlagen hinaus)
Sie kennen die Lehrbuchdefinitionen. In der Praxis kommt es darauf an, die Fehlermodi der einzelnen Ansätze zu verstehen.
Fine-Tuning in der Produktion
Fine-Tuning passt die Modellgewichte mithilfe eines kuratierten Datensatzes aus (Prompt, Completion)-Paaren an. Das Ergebnis ist ein Modell, das Muster, Terminologie und Verhalten aus Ihren Trainingsdaten in seine Parameter aufgenommen hat. Der klassische Enterprise-Ansatz: ein feinabgestimmtes Modell, kein Retrieval-Overhead, schnelle Inferenz.
Die versteckten Kosten: Ein Fine-Tuning-Durchlauf für ein 7B-Parametermodell mit QLoRA auf einer einzelnen A100 80GB dauert 4–12 Stunden und kostet bei Cloud-GPU-Preisen (Stand Q1 2026) grob 40–120 Dollar. Für ein 70B-Modell multipliziert sich das mit dem Faktor 8–10. Und das ist nur der erste Durchlauf. Jedes Mal, wenn sich Ihre Wissensbasis ändert – ein Produkt-Update, eine Richtlinienüberarbeitung, eine neue Vorschrift –, müssen Sie entweder neu trainieren oder ein veraltetes Modellverhalten in Kauf nehmen. Die meisten Unternehmenswissensdomänen ändern sich wöchentlich oder täglich.
Die Verschlechterung der Genauigkeit ist die andere Falle. Ein feinabgestimmtes Modell kann selbstbewusst Informationen aus seiner Trainingsverteilung halluzinieren, die inzwischen veraltet sind. Eine interne Analyse von Morgan Stanley zu ihrem KI-Assistenten-Piloten (offengelegt in einem Telefonat zu den Geschäftsergebnissen 2025) ergab, dass feinabgestimmte Modelle für Finanzdaten alle 6–8 Wochen vollständig neu trainiert werden mussten, um eine akzeptable Genauigkeit bei den aktuellen Marktbedingungen zu gewährleisten, was Kosten von über 200.000 Dollar pro Quartal allein für GPU-Computing verursachte.
RAG in der Produktion
Eine RAG-Pipeline ruft zur Inferenzzeit relevante Dokumentabschnitte aus einem Vektor-Store ab und fügt sie in den Kontextfenster des Modells ein. Das Modell schlussfolgert auf der Grundlage der abgerufenen Beweise und verlässt sich nicht ausschließlich auf die trainierten Gewichte.
Die Hauptvorteile sind Aktualität und Prüfbarkeit. Wenn sich Ihre Wissensdatenbank ändert, aktualisieren Sie den Vektorindex – ein Vorgang, der für inkrementelle Aktualisierungen Minuten und für eine vollständige Neuindizierung Stunden dauert. Kein erneutes Modelltraining erforderlich. Sie erhalten außerdem eine Quellenattribuierung: Jede Antwort kann den genauen Dokumentabschnitt zitieren, auf dem sie basiert, was für regulierte Branchen enorm wichtig ist.
Die eigentlichen Fehlermodi: Die Retrieval-Qualität ist der Engpass. Eine naive Kosinus-Ähnlichkeitssuche über Embeddings ruft zwar annähernd den richtigen Inhalt ab, übersieht aber nuancierte mehrstufige Reasoning-Ketten. Produktive RAG-Systeme bei Unternehmen wie Salesforce und ServiceNow sind zu einem hybriden Retrieval (dichte + sparse BM25) plus einem Re-Ranking mit einem Cross-Encoder übergegangen, was ~80–120 ms Latenz pro Abfrage hinzufügt, aber die Antwortgenauigkeit bei internen Benchmarks um 15–25 % verbessert.
Direkter Vergleich: Kosten, Latenz, Genauigkeit
Gesamtbetriebskosten (jährlich, mittelständisches Unternehmen)
Angenommen werden 10 Millionen Abfragen/Jahr, eine 50.000 Dokumente umfassende, wöchentlich aktualisierte Wissensdatenbank und ein GPT-4o-ähnliches Modell.
- Fine-Tuning-Ansatz: Erstes Fine-Tuning (800–2.000 $) + wöchentliches Neutraining (400–1.200 $/Woche) + Inferenz auf gehostetem, feinabgestimmten Modell (3.000–6.000 $/Monat) = 85.000–140.000 $/Jahr
- RAG-Ansatz: Hosting der Vektordatenbank (Pinecone, Weaviate oder pgvector auf RDS) (200–800 $/Monat) + Embedding-Generierung für wöchentliche Updates (50–200 $/Monat) + Basismodell-Inferenz (4.000–8.000 $/Monat) = 52.000–108.000 $/Jahr
RAG ist in dieser Größenordnung 20–40 % günstiger. Die Lücke vergrößert sich dramatisch, wenn die Aktualisierungshäufigkeit des Wissens zunimmt.
Latenz
- Feinabgestimmtes Modell (kein Retrieval): 200–400 ms p95 für eine 500-Token-Antwort auf einem dedizierten GPU-Endpunkt
- RAG-Pipeline (Embedding + Vektorsuche + LLM): 400–900 ms p95 in Abhängigkeit von der Retrieval-Komplexität und dem Re-Ranking
- Feinabgestimmtes Modell + RAG (hybrid): 500–1.100 ms p95
Fine-Tuning liegt bei der reinen Latenz um 200–500 ms vorne. Für die meisten Unternehmensanwendungen – interne Copiloten, Dokumentationssuche, Kundensupport – ist dieser Unterschied für die Benutzer nicht wahrnehmbar. Er ist wichtig für Echtzeitanwendungen wie Sprachschnittstellen (bei denen weniger als 500 ms eine harte Anforderung sind) oder Handelssysteme, bei denen Millisekunden einen direkten Geldwert haben.
Genauigkeit bei wissensintensiven Aufgaben
Im FRAMES-Benchmark (einer mehrdokumentigen QA-Auswertungssuite, die 2025 zum De-facto-Standard für die RAG-Bewertung wurde) erreichte eine gut abgestimmte RAG-Pipeline mit GPT-4o 72–78 % Genauigkeit bei unternehmensüblichen Multi-Hop-Fragen. Ein feinabgestimmtes GPT-4o in derselben Domäne erzielte 61–67 % – niedriger, weil das feinabgestimmte Modell aus einstudierten Mustern und nicht aus abgerufenen Belegen antwortete und der Testsatz Fragen zu Informationen enthielt, die sich nach dem Trainingsstichtag geändert hatten.
Bei Klassifikations- und Extraktionsaufgaben mit festen Schemata gewinnt Fine-Tuning: Ein feinabgestimmtes Llama 3.1 8B-Modell zur strukturierten Datenextraktion erreichte eine Feldgenauigkeit von 94 % gegenüber 87 % bei einem per Prompt gesteuerten GPT-4o mit RAG-Kontext, bei 1/8 der Inferenzkosten.
Wann Fine-Tuning tatsächlich die richtige Wahl ist
Es gibt vier Szenarien, in denen Fine-Tuning RAG übertrifft und die Kompromisse gerechtfertigt sind:
1. Spezialisierter domänenspezifischer Wortschatz und Reasoning
Medizinische Bildberichterstellung, Klassifizierung von Vertragsklauseln im Rechtswesen, Chip-Design-Verifikation – Domänen, in denen die Terminologie, die Denkmuster und die Ausgabeformate so spezialisiert sind, dass ein Basismodell bei jeder Abfrage Hunderte von Token an kontextueller Erklärung benötigt. Fine-Tuning amortisiert diese Kontextkosten über alle Inferenzen hinweg. Das klinische Zusammenfassungsmodell von Hippocratic AI und das Vertragsanalysesystem von Harvey AI stützen sich genau deshalb auf Fine-Tuning, weil ihre Domänen Denkmuster erfordern, die sich durch reine Prompt-Steuerung nicht zuverlässig hervorrufen lassen.
2. Strenge Latenzanforderungen (unter 300 ms)
Sprachschnittstellen, Echtzeit-Codierungsassistenten, die in IDEs integriert sind (wie die Autovervollständigung von Cursor), und Edge-KI auf Geräten, bei denen keine Retrieval-Infrastruktur verfügbar ist. Ein lokal laufendes, feinabgestimmtes 3B–7B-Modell ist die einzig praktikable Architektur, wenn eine Antwort in unter 300 ms ohne Netzwerk-Roundtrip erforderlich ist.
3. Konsistentes Ausgabeformat und konsistenter Stil
Wenn Ihre Anwendung Ausgaben in einem hochspezifischen Format erzeugt – strukturiertes JSON mit einem proprietären Schema, der exakte Schreibstil einer Marke, ein bestimmtes Programmierparadigma –, dann verankert Fine-Tuning dieses Format zuverlässiger als Prompt-Engineering. Code-Vervollständigungstools im Copilot-Stil von GitHub und JetBrains verwenden aus diesem Grund Fine-Tuning.
4. Daten dürfen Ihre Umgebung nicht verlassen
Einige Unternehmen können aufgrund von Datenhoheitsvorschriften (EU-AI-Act Artikel 28 Datenverarbeitungsanforderungen, HIPAA, FedRAMP) keine Dokumente an eine externe Vektor-DB oder LLM-API senden. Ein vollständig lokales, feinabgestimmtes Modell ohne Retrieval-Abhängigkeit ist architektonisch einfacher als ein lokaler RAG-Stack, obwohl letzterer mit selbst gehosteten Weaviate- oder Qdrant-Clustern zunehmend praktikabel ist.
Wann RAG die richtige Wahl ist (in den meisten Fällen)
RAG ist die richtige Standardeinstellung für Unternehmensbereitstellungen, wenn:
- Ihre Wissensdatenbank sich häufiger als vierteljährlich ändert
- Sie eine Quellenattribuierung für Compliance oder das Vertrauen der Benutzer benötigen
- Ihre Abfrageverteilung breit ist (Fragen umfassen viele Themen, nicht nur eine enge Domäne)
- Sie mit einer Wissensdatenbank arbeiten, die größer als 10.000 Dokumente ist, bei der das Auswendiglernen durch Fine-Tuning unzuverlässig wird
- Sie Modell-Upgrades ohne Neutrainings-Pipelines A/B-testen möchten
Alle verwenden RAG-first-Architekturen: der KI-Assistent Rovo von Atlassian, Notion AI und das Produkt Fin von Intercom. Der gemeinsame Nenner: Ihre Wissensdatenbanken (Confluence-Seiten, Notion-Dokumente, Kundensupport-Tickets) ändern sich kontinuierlich, und Aktualität ist nicht verhandelbar.
Die hybride Architektur: Wohin die Produktion steuert
Die leistungsfähigsten Enterprise-KI-Systeme im Jahr 2026 verwenden Fine-Tuning und RAG zusammen, aber auf eine bestimmte Weise. Das Basis-LLM wird hinsichtlich Aufgabenformat und Reasoning-Stil feinabgestimmt – nicht auf Faktenwissen. Das Faktenwissen lebt vollständig in der Retrieval-Schicht. Diese Trennung der Zuständigkeiten wird manchmal als "Format-Fine-Tuning + Wissens-RAG" bezeichnet.
Das Enterprise-Modell Command R+ von Cohere basiert auf diesem Prinzip: Das Modell wurde für RAG-spezifisches Reasoning (Zitatausrichtung, Evidenzsynthese, mehrstufige Gedankenketten) instruktions-abgestimmt und nicht auf domänenspezifische Fakten. Kunden integrieren ihre eigenen Wissensdatenbanken. Das Ergebnis: eine bessere Nutzung des Retrievals als bei einem generischen Basismodell, ohne die Last des Neutrainings von Faktenwissen.
Entscheidungsrahmen: Ein praktisches Flussdiagramm
Beantworten Sie diese Fragen der Reihe nach:
- Ändert sich Ihre Wissensdatenbank mehr als einmal pro Quartal? Ja → RAG. Nein → weiter.
- Benötigen Sie Quellenattribuierung oder Prüfpfade? Ja → RAG. Nein → weiter.
- Ist die p95-Latenz eine harte Anforderung unter 300 ms? Ja → Fine-Tuning. Nein → weiter.
- Ist Ihre Domäne so spezialisiert, dass ein Basismodell System-Prompts mit 500+ Token benötigt, um sich korrekt zu verhalten? Ja → Fine-Tuning (oder hybrid). Nein → RAG.
- Verhindern Datenhoheitsvorschriften externe API-Aufrufe? Ja → Bewerten Sie On-Premise-RAG vs. lokales, feinabgestimmtes Modell basierend auf der Infrastrukturkomplexität. Nein → RAG.
Umsetzbare Erkenntnisse
- Beginnen Sie mit RAG. Der Infrastrukturaufwand ist geringer, die Iteration ist schneller, und Sie können später jederzeit Fine-Tuning für bestimmte Komponenten hinzufügen. Das Gegenteil – das Rückgängigmachen einer Fine-Tuning-Investition – ist teuer.
- Wenn Sie Fine-Tuning durchführen, dann für das Verhalten, nicht für Fakten. Trainieren Sie auf Reasoning-Muster, Ausgabeformat und Aufgabenstruktur. Bewahren Sie Fakten in der Retrieval-Schicht auf.
- Investieren Sie vor der Skalierung in die Retrieval-Qualität. Das hybride BM25 + dichte Retrieval mit einem Cross-Encoder-Re-Ranker ist in der Produktion nicht mehr optional, sondern der Basiss tandard. Ein billiges Kosinus-Ähnlichkeits-RAG wird unter einem gut per Prompt gesteuerten Basismodell abschneiden.
- Messen Sie die Aktualität getrennt von der Genauigkeit. Ein Modell kann in einem statischen Benchmark gut abschneiden, während es in der Produktion veraltete Antworten liefert. Erstellen Sie Evaluierungssets aus Dokumenten, die nach Ihrem Trainingsstichtag hinzugefügt wurden.
- Für Edge/On-Device: Verwenden Sie quantisierte, feinabgestimmte Modelle (GGUF Q4_K_M auf llama.cpp) – RAG ist ohne zuverlässigen Netzwerkzugang unpraktisch.