فاینتیونینگ در مقابل RAG: کدام رویکرد واقعاً برای هوش مصنوعی سازمانی در سال ۲۰۲۶ مؤثر است؟
RAG در بیشتر نبردهای سازمانی پیروز میشود — اما Fine-tuning همچنان نقش خود را دارد
برای اکثر قریب به اتفاق موارد استفاده هوش مصنوعی سازمانی در سال ۲۰۲۶، Retrieval-Augmented Generation (RAG) بازگشت سرمایه (ROI) بهتری نسبت به fine-tuning یک مدل پایه ارائه میدهد. این یک تبلیغ فروشنده نیست. این نتیجهای است که وقتی به هزینه کل مالکیت، تاخیر بهروزرسانی و معیارهای دقت در استقرارهای واقعی نگاه میکنید، به آن میرسید. Fine-tuning همچنان در مجموعهای محدود اما مهم از سناریوها انتخاب درستی است: تطبیق دامنه بسیار تخصصی، استنتاج لبه با محدودیت تاخیر (latency)، و وظایف یکنواختی سبک/فرمت که در آنها هیچ بازیابی خارجی قابل قبول نیست.
این مطلب دقیقاً توضیح میدهد که چرا، همراه با اعداد. اگر یک مهندس هوش مصنوعی هستید که بین دو رویکرد برای یک پایگاه دانش داخلی، یک دستیار مشتری، یا یک طبقهبندیکننده خاص دامنه تصمیم میگیرید، این چارچوب ماهها تکرار پرهزینه را برای شما کاهش میدهد.
هر رویکرد واقعاً چه کاری انجام میدهد (فراتر از اصول اولیه)
شما تعاریف کتاب درسی را میدانید. آنچه در عمل اهمیت دارد، درک حالتهای شکست هر یک است.
Fine-tuning در تولید
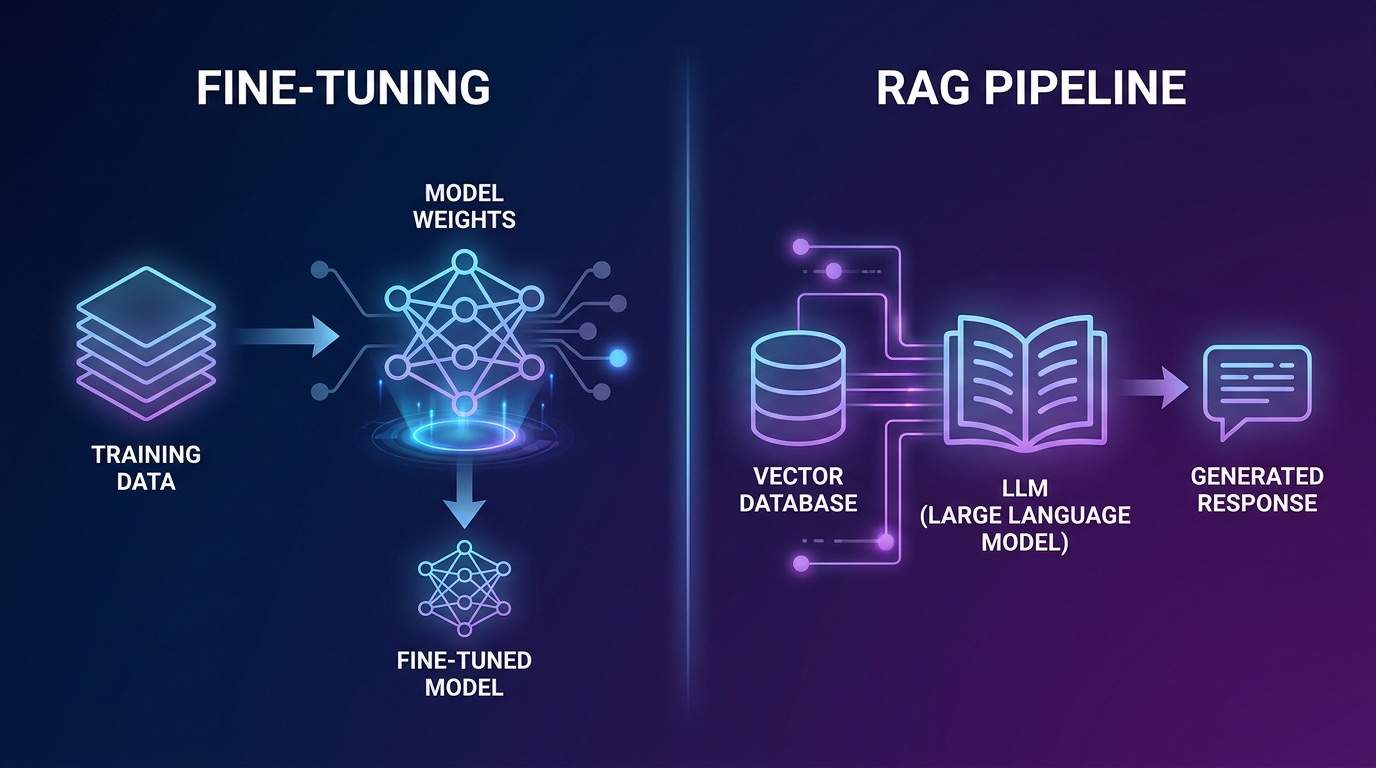
Fine-tuning وزنهای مدل را با استفاده از یک مجموعه دادهی منظم از جفتهای (prompt, completion) تنظیم میکند. نتیجه یک مدل است که الگوها، اصطلاحات و رفتار را از دادههای آموزشی شما در پارامترهای خود جذب کرده است. وعده کلاسیک سازمانی: یک مدل fine-tuned، بدون سربار بازیابی و استنتاج سریع.
هزینههای پنهان: اجرای fine-tuning بر روی یک مدل ۷ میلیارد پارامتری با استفاده از QLoRA روی یک A100 80GB، ۴ تا ۱۲ ساعت طول میکشد و با قیمتهای GPU ابری از سهماهه اول ۲۰۲۶، تقریباً ۴۰ تا ۱۲۰ دلار هزینه دارد. برای یک مدل ۷۰ میلیارد پارامتری، این هزینه را ۸ تا ۱۰ برابر کنید. این فقط اولین اجراست. هر بار که پایگاه دانش شما تغییر میکند (یک بهروزرسانی محصول، یک بازبینی خط مشی، یک مقررات جدید)، یا باید دوباره آموزش دهید یا رفتار مدل قدیمی را بپذیرید. بیشتر حوزههای دانش سازمانی به صورت هفتگی یا روزانه تغییر میکنند.
تخریب دقت، تله دیگر است. یک مدل fine-tuned میتواند با اطمینان اطلاعاتی را از توزیع آموزشی خود که اکنون قدیمی شده است، توهم بزند (hallucinate). تحلیل داخلی Morgan Stanley از دستیار هوش مصنوعی خود (که در یک تماس درآمدی در سال ۲۰۲۵ افشا شد) نشان داد که مدلهای fine-tuned روی دادههای مالی برای حفظ دقت قابل قبول در شرایط فعلی بازار، هر ۶ تا ۸ هفته به آموزش مجدد کامل نیاز داشتند که تنها هزینه GPU آن بیش از ۲۰۰ هزار دلار در هر سه ماه بود.
RAG در تولید
یک خط لوله RAG، تکههای سند مرتبط را از یک ذخیرهسازی برداری (vector store) در زمان استنتاج بازیابی میکند و آنها را به پنجره زمینه (context window) مدل تزریق میکند. مدل به جای تکیه صرف بر وزنهای آموزشدیده، بر اساس شواهد بازیابیشده استدلال میکند.
مزایای کلیدی، تازگی (freshness) و قابلیت حسابرسی (auditability) هستند. وقتی پایگاه دانش شما تغییر میکند، شما فهرست برداری (vector index) را بهروز میکنید. این عملیات برای بهروزرسانیهای افزایشی چند دقیقه و برای فهرستسازی مجدد کامل چند ساعت طول میکشد. نیازی به آموزش مجدد مدل نیست. همچنین انتساب منبع (source attribution) دریافت میکنید: هر پاسخ میتواند تکه سند دقیقی را که بر آن اساس استوار است، ذکر کند. این موضوع برای صنایع تحت نظارت بسیار مهم است.
حالتهای شکست واقعی: کیفیت بازیابی، گلوگاه است. یک جستجوی ساده شباهت کسینوسی (cosine similarity) بر روی جاسازیها (embeddings) محتوای تقریباً درستی را بازیابی میکند، اما زنجیرههای استدلال چندمرحلهای ظریف را از دست میدهد. سیستمهای RAG تولیدی در شرکتهایی مانند Salesforce و ServiceNow به سمت بازیابی ترکیبی (hybrid retrieval) (BM25 متراکم + تنک) به همراه مرتبسازی مجدد (re-ranking) با یک رمزگذار متقاطع (cross-encoder) حرکت کردهاند. این کار حدود ۸۰ تا ۱۲۰ میلیثانیه تاخیر به هر پرس و جو اضافه میکند، اما دقت پاسخ را در معیارهای داخلی ۱۵ تا ۲۵ درصد بهبود میبخشد.
مقایسه رو در رو: هزینه، تاخیر، دقت
هزینه کل مالکیت (سالانه، مقیاس متوسط سازمانی)
فرض کنید ۱۰ میلیون پرس و جو در سال، یک پایگاه دانش ۵۰ هزار سندی که به صورت هفتگی بهروز میشود و یک مدل کلاس GPT-4o دارید.
- رویکرد Fine-tuning: fine-tuning اولیه (۸۰۰ تا ۲۰۰۰ دلار) + آموزش مجدد هفتگی (۴۰۰ تا ۱۲۰۰ دلار در هفته) + استنتاج بر روی میزبانی مدل fine-tuned (۳۰۰۰ تا ۶۰۰۰ دلار در ماه) = ۸۵,۰۰۰ تا ۱۴۰,۰۰۰ دلار در سال
- رویکرد RAG: میزبانی پایگاه داده برداری (Pinecone، Weaviate، یا pgvector روی RDS) (۲۰۰ تا ۸۰۰ دلار در ماه) + تولید جاسازی (embedding) برای بهروزرسانیهای هفتگی (۵۰ تا ۲۰۰ دلار در ماه) + استنتاج مدل پایه (۴۰۰۰ تا ۸۰۰۰ دلار در ماه) = ۵۲,۰۰۰ تا ۱۰۸,۰۰۰ دلار در سال
RAG در این مقیاس ۲۰ تا ۴۰ درصد ارزانتر است. این شکاف با افزایش دفعات بهروزرسانی دانش به طرز چشمگیری بیشتر میشود.
تاخیر (Latency)
- مدل Fine-tuned (بدون بازیابی): ۲۰۰ تا ۴۰۰ میلیثانیه p95 برای یک پاسخ ۵۰۰ توکنی در یک نقطه پایانی GPU اختصاصی
- خط لوله RAG (جاسازی + جستجوی برداری + LLM): ۴۰۰ تا ۹۰۰ میلیثانیه p95 بسته به پیچیدگی بازیابی و مرتبسازی مجدد
- مدل Fine-tuned + RAG (ترکیبی): ۵۰۰ تا ۱۱۰۰ میلیثانیه p95
Fine-tuning با ۲۰۰ تا ۵۰۰ میلیثانیه در تاخیر خام پیروز میشود. برای اکثر برنامههای سازمانی (دستیارهای داخلی، جستجوی اسناد، پشتیبانی مشتری)، این تفاوت برای کاربران غیرقابل درک است. این موضوع برای برنامههای بلادرنگ مانند رابطهای صوتی (جایی که کمتر از ۵۰۰ میلیثانیه یک نیاز سخت است) یا سیستمهای معاملاتی (که میلیثانیهها ارزش دلاری مستقیم دارند) اهمیت دارد.
دقت در وظایف دانش-فشرده
در معیار FRAMES (یک مجموعه ارزیابی QA چند سندی که در سال ۲۰۲۵ به استاندارد واقعی برای ارزیابی RAG تبدیل شد)، یک خط لوله RAG خوب تنظیمشده با استفاده از GPT-4o به دقت ۷۲ تا ۷۸ درصد در سوالات چندمرحلهای به سبک سازمانی دست یافت. یک GPT-4o fine-tuned روی همان دامنه، امتیاز ۶۱ تا ۶۷ درصد را کسب کرد. این کمتر است، زیرا مدل fine-tuned از الگوهای حفظشده به جای شواهد بازیابیشده پاسخ میداد و مجموعه آزمایشی شامل سوالاتی درباره اطلاعاتی بود که پس از قطع آموزش تغییر کرده بودند.
برای وظایف طبقهبندی و استخراج با طرحوارههای ثابت، fine-tuning برنده است: یک مدل fine-tuned Llama 3.1 8B برای استخراج دادههای ساختاریافته به دقت ۹۴ درصد در سطح فیلد در مقابل ۸۷ درصد برای یک GPT-4o با زمینه RAG و با یک هشتم هزینه استنتاج دست یافت.
زمانی که Fine-tuning واقعاً انتخاب درستی است
چهار سناریو وجود دارد که در آنها fine-tuning از RAG بهتر عمل میکند و معاوضهها توجیهپذیر هستند:
۱. واژگان و استدلال دامنه تخصصی
تولید گزارش تصویربرداری پزشکی، طبقهبندی بندهای قرارداد حقوقی، تأیید طراحی تراشه. حوزههایی که اصطلاحات، الگوهای استدلال و قالبهای خروجی آنها به قدری تخصصی است که یک مدل پایه برای هر پرس و جو به صدها توکن توضیح درون زمینهای (in-context explanation) نیاز دارد. Fine-tuning هزینه آن زمینه را در تمام استنتاجها پخش میکند. مدل خلاصهسازی بالینی Hippocratic AI و سیستم تحلیل قرارداد Harvey AI هر دو دقیقاً به همین دلیل بر fine-tuning تکیه میکنند، زیرا حوزههای آنها به الگوهای استدلالی نیاز دارد که به طور قابل اعتمادی تنها از طریق مهندسی prompt (prompting) قابل استخراج نیستند.
۲. الزامات تاخیر سخت (کمتر از ۳۰۰ میلیثانیه)
رابطهای صوتی، دستیارهای کدنویسی بلادرنگ یکپارچهشده در IDEها (مانند ویژگی تکمیل خودکار Cursor)، و هوش مصنوعی لبه روی دستگاه که زیرساخت بازیابی در آن در دسترس نیست. یک مدل fine-tuned 3B-7B که به صورت محلی اجرا میشود، تنها معماری قابل دوام زمانی است که به پاسخی زیر ۳۰۰ میلیثانیه بدون رفت و برگشت شبکه نیاز دارید.
۳. قالب و سبک خروجی یکنواخت
اگر برنامه شما خروجیهایی با قالبی بسیار خاص تولید میکند (JSON ساختاریافته با یک طرحواره اختصاصی، سبک نوشتاری دقیق یک برند، یک اصطلاح خاص زبان برنامهنویسی)، fine-tuning آن قالب را به طور قابل اطمینانتری نسبت به مهندسی prompt تثبیت میکند. ابزارهای تکمیل کد به سبک Copilot از GitHub و JetBrains به همین دلیل از fine-tuning استفاده میکنند.
۴. دادهها نمیتوانند محیط شما را ترک کنند
برخی از سازمانها به دلیل مقررات حاکمیت داده (الزامات پردازش داده ماده ۲۸ قانون هوش مصنوعی اتحادیه اروپا، HIPAA، FedRAMP) نمیتوانند اسناد را به یک پایگاه داده برداری خارجی یا API LLM ارسال کنند. یک مدل fine-tuned کاملاً درونسازمانی (on-premise) با عدم وابستگی به بازیابی، از نظر معماری سادهتر از یک پشته RAG درونسازمانی است، اگرچه راهحل دوم به طور فزایندهای با کلاسترهای خودمیزبان Weaviate یا Qdrant امکانپذیر است.
زمانی که RAG انتخاب درستی است (در بیشتر مواقع)
RAG پیشفرض صحیح برای استقرارهای سازمانی زمانی است که:
- پایگاه دانش شما بیش از یکبار در سه ماه تغییر میکند
- برای انطباق یا اعتماد کاربر به انتساب منبع نیاز دارید
- توزیع پرس و جوی شما گسترده است (سوالات موضوعات زیادی را پوشش میدهند، نه یک دامنه محدود)
- با یک پایگاه دانش بزرگتر از ۱۰,۰۰۰ سند کار میکنید، جایی که حفظسازی fine-tuning غیرقابل اعتماد میشود
- میخواهید ارتقاء مدل را بدون خطوط لوله آموزش مجدد A/B تست کنید
دستیار هوش مصنوعی Rovo از Atlassian، Notion AI و محصول Fin از Intercom همگی از معماریهای اولویتدار RAG (RAG-first) استفاده میکنند. وجه مشترک آنها: پایگاههای دانش آنها (صفحات Confluence، اسناد Notion، تیکتهای پشتیبانی مشتری) به طور مداوم تغییر میکنند و تازگی (freshness) غیرقابل مذاکره است.
معماری ترکیبی: جایی که تولید در حال حرکت است
قویترین سیستمهای هوش مصنوعی سازمانی در سال ۲۰۲۶ از fine-tuning و RAG با هم استفاده میکنند، اما به روشی خاص. LLM پایه بر روی فرمت وظیفه و سبک استدلال fine-tuning میشود، نه بر روی دانش واقعی. دانش واقعی کاملاً در لایه بازیابی قرار دارد. این جداسازی دغدغهها گاهی "format fine-tuning + knowledge RAG" نامیده میشود.
مدل سازمانی Command R+ از Cohere بر اساس همین اصل ساخته شده است: این مدل برای استدلال خاص RAG (مستندسازی استناد، ترکیب شواهد، زنجیره فکر چندمرحلهای) به جای حقایق دامنه، آموزش داده شده است. مشتریان پایگاههای دانش خود را متصل میکنند. نتیجه: استفاده بهتر از بازیابی نسبت به یک مدل پایه عمومی، بدون بار آموزش مجدد دانش ناشی از fine-tuning دانش.
چارچوب تصمیمگیری: یک نمودار جریان عملی
به این سوالات به ترتیب پاسخ دهید:
- آیا پایگاه دانش شما بیش از یک بار در سه ماه تغییر میکند؟ بله → RAG. خیر → ادامه دهید.
- آیا به انتساب منبع یا مسیرهای حسابرسی نیاز دارید؟ بله → RAG. خیر → ادامه دهید.
- آیا تاخیر p95 یک نیاز سخت زیر ۳۰۰ میلیثانیه است؟ بله → Fine-tuning. خیر → ادامه دهید.
- آیا دامنه شما