Fine-tuning vs. RAG : Quelle approche fonctionne réellement pour l'IA en entreprise en 2026
RAG remporte la plupart des batailles en entreprise — mais le Fine-tuning a toujours un rôle à jouer
Pour la grande majorité des cas d'usage de l'IA en entreprise en 2026, le Retrieval-Augmented Generation (RAG) offre un meilleur retour sur investissement que le fine-tuning d'un modèle de base. Ce n'est pas un argument commercial — c'est la conclusion à laquelle on arrive en examinant le coût total de possession, la latence de mise à jour et les benchmarks de précision pour des déploiements réels. Le fine-tuning reste la bonne approche dans un ensemble restreint mais important de scénarios : adaptation à un domaine hautement spécialisé, inférence en périphérie avec contrainte de latence, et tâches de cohérence de style/format où aucune récupération externe n'est acceptable.
Ce post détaille exactement pourquoi, avec des chiffres. Si vous êtes un ingénieur IA qui doit choisir entre les deux approches pour une base de connaissances interne, un copilote destiné aux clients, ou un classifieur spécialisé par domaine, voici le cadre qui vous fera économiser des mois d'itérations coûteuses.
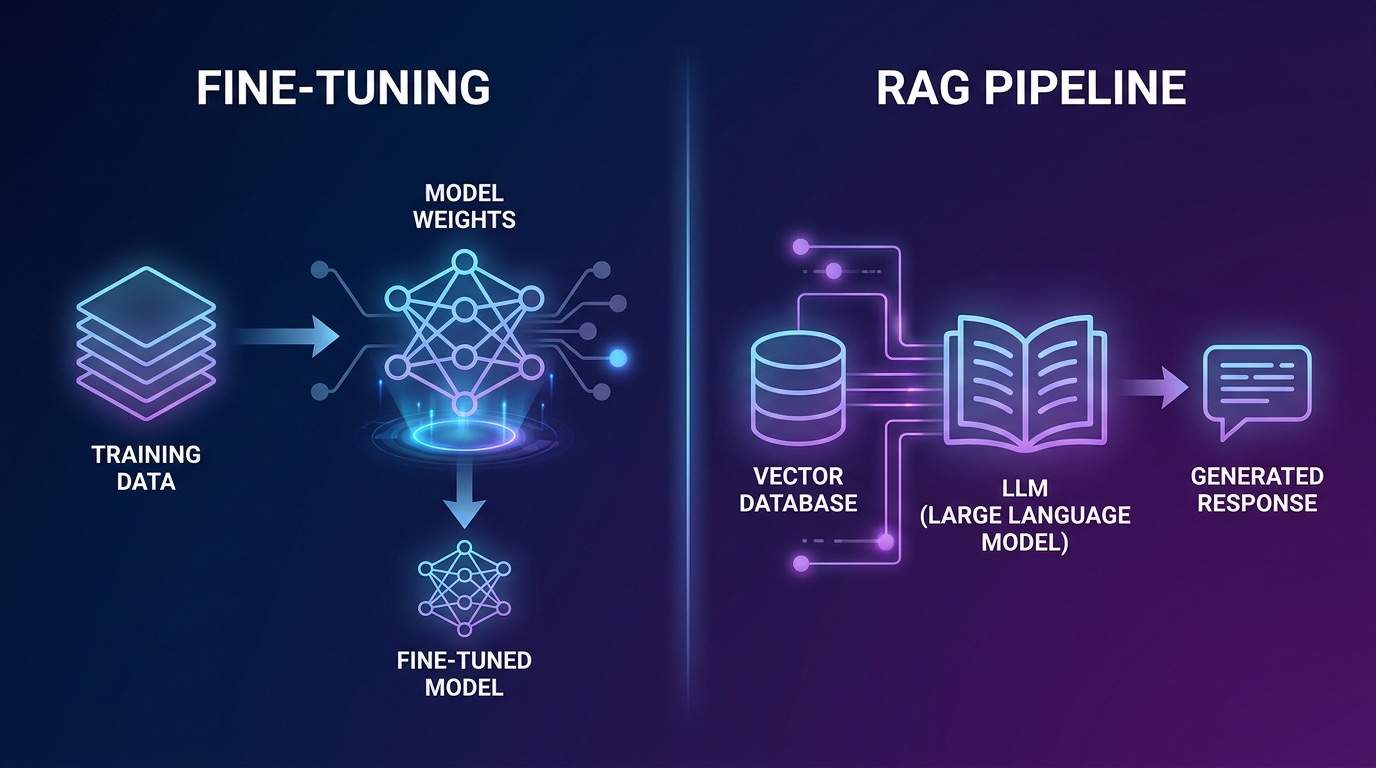
Ce que chaque approche fait réellement (au-delà des bases)
Vous connaissez les définitions théoriques. Ce qui compte en pratique, c'est de comprendre les modes de défaillance de chacune.
Le Fine-tuning en production
Le fine-tuning ajuste les poids du modèle à l'aide d'un ensemble de données constitué de paires (invite, réponse). Le résultat est un modèle qui a intégré dans ses paramètres les modèles, la terminologie et le comportement de vos données d'entraînement. L'argument commercial classique en entreprise : un modèle fine-tuné, aucun overhead de récupération, une inférence rapide.
Les coûts cachés : Un run de fine-tuning sur un modèle de 7B de paramètres utilisant QLoRA sur un seul A100 80 Go prend 4 à 12 heures et coûte environ 40 à 120 dollars sur les tarifs cloud GPU du T1 2026. Pour un modèle de 70B, multipliez par 8 à 10. Et ce n'est que le premier run. Chaque fois que votre base de connaissances change — une mise à jour produit, une révision de politique, une nouvelle réglementation — vous devez soit ré-entraîner, soit accepter un comportement obsolète du modèle. La plupart des domaines de connaissances en entreprise changent hebdomadairement ou quotidiennement.
La dégradation de la précision est l'autre piège. Un modèle fine-tuné peut halluciner avec assurance des informations issues de sa distribution d'entraînement qui sont désormais obsolètes. L'analyse interne de Morgan Stanley concernant le pilote de leur assistant IA (divulguée lors d'une conférence téléphonique sur les résultats en 2025) a montré que les modèles fine-tunés sur des données financières nécessitaient un ré-entraînement complet toutes les 6 à 8 semaines pour maintenir une précision acceptable sur les conditions de marché actuelles, pour un coût de plus de 200 000 dollars par trimestre en seul calcul GPU.
Le RAG en production
Un pipeline RAG récupère des extraits de documents pertinents depuis un stockage vectoriel au moment de l'inférence et les injecte dans la fenêtre de contexte du modèle. Le modèle raisonne à partir des preuves récupérées plutôt que de se fier uniquement à ses poids entraînés.
Les avantages clés sont la fraîcheur et l'auditabilité. Lorsque votre base de connaissances change, vous mettez à jour l'index vectoriel — une opération qui prend quelques minutes pour les mises à jour incrémentales et des heures pour une réindexation complète. Aucun ré-entraînement de modèle requis. Vous bénéficiez également de l'attribution des sources : chaque réponse peut citer l'extrait de document exact sur lequel elle se fonde, ce qui est extrêmement important pour les secteurs réglementés.
Les véritables modes de défaillance : la qualité de la récupération est le goulot d'étranglement. Une recherche par similarité cosinus naïve sur des embeddings récupère approximativement le bon contenu mais manque les chaînes de raisonnement multi-sauts nuancées. Les systèmes RAG de production chez des entreprises comme Salesforce et ServiceNow sont passés à la récupération hybride (dense + sparse BM25) avec un re-ranking utilisant un cross-encoder, ajoutant environ 80 à 120 ms de latence par requête mais améliorant la précision des réponses de 15 à 25 % sur les benchmarks internes.
Comparaison directe : Coût, Latence, Précision
Coût Total de Possession (Annuel, Entreprise de Taille Moyenne)
Supposons 10 millions de requêtes/an, une base de connaissances de 50 000 documents mise à jour chaque semaine, et un modèle de classe GPT-4o.
- Approche Fine-tuning : Fine-tuning initial (800–2 000 $) + ré-entraînement hebdomadaire (400–1 200 $/semaine) + hébergement du modèle fine-tuné pour l'inférence (3 000–6 000 $/mois) = 85 000–140 000 $/an
- Approche RAG : Hébergement de la base de données vectorielle (Pinecone, Weaviate, ou pgvector sur RDS) (200–800 $/mois) + génération d'embeddings pour les mises à jour hebdomadaires (50–200 $/mois) + inférence du modèle de base (4 000–8 000 $/mois) = 52 000–108 000 $/an
Le RAG est 20 à 40 % moins cher à cette échelle. L'écart se creuse considérablement lorsque la fréquence de mise à jour des connaissances augmente.
Latence
- Modèle fine-tuné (sans récupération) : 200–400 ms p95 pour une réponse de 500 tokens sur un endpoint GPU dédié
- Pipeline RAG (embedding + recherche vectorielle + LLM) : 400–900 ms p95 selon la complexité de la récupération et le re-ranking
- Modèle fine-tuné + RAG (hybride) : 500–1 100 ms p95
Le fine-tuning gagne sur la latence brute de 200 à 500 ms. Pour la plupart des applications d'entreprise — copilotes internes, recherche documentaire, support client — cette différence est imperceptible pour les utilisateurs. Elle est importante pour les applications en temps réel comme les interfaces vocales (où moins de 500 ms est une exigence stricte) ou les systèmes de trading où les millisecondes ont une valeur monétaire directe.
Précision sur les tâches à forte intensité de connaissances
Sur le benchmark FRAMES (une suite d'évaluation de QA multi-documents devenue la norme de facto pour l'évaluation RAG en 2025), un pipeline RAG bien réglé utilisant GPT-4o a atteint 72–78 % de précision sur des questions multi-sauts de type entreprise. Un GPT-4o fine-tuné sur le même domaine a obtenu 61–67 % — moins élevé, car le modèle fine-tuné répondait à partir de modèles mémorisés plutôt que de preuves récupérées, et l'ensemble de test incluait des questions sur des informations ayant changé après la date limite d'entraînement.
Pour les tâches de classification et d'extraction avec des schémas fixes, le fine-tuning gagne : un modèle Llama 3.1 8B fine-tuné pour l'extraction de données structurées a atteint 94 % de précision au niveau du champ contre 87 % pour un GPT-4o avec contexte RAG, pour 1/8e du coût d'inférence.
Quand le Fine-tuning est réellement la bonne approche
Il existe quatre scénarios où le fine-tuning surpasse le RAG et où les compromis sont justifiés :
1. Vocabulaire et Raisonnement de Domaine Spécialisé
Génération de rapports d'imagerie médicale, classification de clauses contractuelles juridiques, vérification de conception de puces — des domaines où la terminologie, les schémas de raisonnement et les formats de sortie sont si spécialisés qu'un modèle de base nécessite des centaines de tokens d'explication contextuelle à chaque requête. Le fine-tuning amortit ce coût de contexte sur toutes les inférences. Le modèle de résumé clinique d'Hippocratic AI et le système d'analyse de contrats de Harvey AI reposent tous deux sur le fine-tuning précisément parce que leurs domaines nécessitent des schémas de raisonnement qui ne peuvent pas être obtenus de manière fiable par le simple prompting.
2. Exigences Strictes de Latence (moins de 300ms)
Interfaces vocales, assistants de codage temps réel intégrés aux environnements de développement (comme la complétion automatique de Cursor), et IA en périphérie sur appareil où l'infrastructure de récupération est indisponible. Un modèle fine-tuné de 3B à 7B fonctionnant localement est la seule architecture viable lorsque vous avez besoin d'une réponse en moins de 300 ms sans allers-retours réseau.
3. Format et Style de Sortie Cohérents
Si votre application génère des sorties dans un format très spécifique — JSON structuré avec un schéma propriétaire, le style d'écriture exact d'une marque, un idiome de langage de programmation particulier — le fine-tuning verrouille ce format de manière plus fiable que l'ingénierie des invites. Les outils de complétion de code de type Copilot de GitHub et JetBrains utilisent le fine-tuning pour cette raison.
4. Les Données ne Peuvent Pas Quitter Votre Environnement
Certaines entreprises ne peuvent pas envoyer de documents à une base vectorielle externe ou à une API LLM en raison des réglementations sur la souveraineté des données (exigences de traitement des données de l'article 28 de l'AI Act de l'UE, HIPAA, FedRAMP). Un modèle fine-tuné entièrement sur site sans dépendance de récupération est architecturalement plus simple qu'une pile RAG sur site, bien que cette dernière soit de plus en plus viable avec des clusters Weaviate ou Qdrant auto-hébergés.
Quand le RAG est la bonne approche (la plupart du temps)
Le RAG est le choix par défaut correct pour les déploiements en entreprise lorsque :
- Votre base de connaissances change plus fréquemment que tous les trimestres
- Vous avez besoin d'une attribution des sources pour la conformité ou la confiance des utilisateurs
- La distribution de vos requêtes est large (les questions couvrent de nombreux sujets, pas un domaine restreint)
- Vous travaillez avec une base de connaissances de plus de 10 000 documents, où la mémorisation par fine-tuning devient peu fiable
- Vous souhaitez effectuer des tests A/B sur les mises à niveau de modèle sans avoir à modifier les pipelines d'entraînement
L'assistant Rovo d'Atlassian, Notion AI et le produit Fin d'Intercom utilisent tous des architectures RAG-first. Le point commun : leurs bases de connaissances (pages Confluence, documents Notion, tickets de support client) changent en continu, et la fraîcheur n'est pas négociable.
L'architecture hybride : là où la production se dirige
Les systèmes d'IA d'entreprise les plus performants en 2026 utilisent le fine-tuning et le RAG ensemble, mais d'une manière spécifique. Le LLM de base est fine-tuné sur le format de la tâche et le style de raisonnement — et non sur la connaissance factuelle. La connaissance factuelle réside entièrement dans la couche de récupération. Cette séparation des préoccupations est parfois appelée "format fine-tuning + knowledge RAG".
Le modèle Command R+ de Cohere pour entreprise est construit sur ce principe : le modèle a été instruction-tuné pour le raisonnement spécifique au RAG (ancrage des citations, synthèse de preuves, chaîne de pensée multi-sauts) plutôt que sur des faits de domaine. Les clients branchent leurs propres bases de connaissances. Le résultat : une meilleure utilisation de la récupération qu'un modèle de base générique, sans le fardeau du ré-entraînement lié au fine-tuning des connaissances.
Cadre de décision : Un organigramme pratique
Répondez à ces questions dans l'ordre :
- Votre base de connaissances change-t-elle plus d'une fois par trimestre ? Oui → RAG. Non → continuez.
- Avez-vous besoin d'attribution des sources ou de pistes d'audit ? Oui → RAG. Non → continuez.
- La latence p95 est-elle une exigence stricte inférieure à 300 ms ? Oui → Fine-tuning. Non → continuez.
- Votre domaine est-il si spécialisé qu'un modèle de base nécessite des invites système de 500+ tokens pour se comporter correctement ? Oui → Fine-tuning (ou hybride). Non → RAG.
- Des règles de souveraineté des données empêchent-elles les appels API externes ? Oui → évaluez le RAG sur site par rapport à un modèle local fine-tuné en fonction de la complexité de l'infrastructure. Non → RAG.
Enseignements Actionnables
- Commencez par le RAG. L'investissement dans l'infrastructure est plus faible, l'itération est plus rapide, et vous pouvez toujours ajouter du fine-tuning plus tard pour des composants spécifiques. L'inverse — défaire un investissement dans le fine-tuning — est coûteux.
- Si vous faites du fine-tuning, faites-le pour le comportement, pas pour les faits. Entraînez sur les schémas de raisonnement, le format de sortie et la structure de la tâche. Conservez les faits dans la couche de récupération.
- Investissez dans la qualité de la récupération avant de passer à l'échelle. La récupération hybride BM25 + dense avec un re-rankeur cross-encoder n'est plus optionnelle pour la production ; c'est la base de référence. Un RAG basé sur une similarité cosinus bon marché sera moins performant qu'un modèle de base bien prompé.
- Mesurez la fraîcheur séparément de la précision. Un modèle peut obtenir un bon score sur un benchmark statique tout en donnant des réponses obsolètes en production. Construisez des ensembles d'évaluation à partir de documents ajoutés après votre date limite d'entraînement.
- Pour la périphérie/sur appareil : utilisez des modèles fine-tunés quantifiés (GGUF Q4_K_M sur llama.cpp) — le RAG est impraticable sans un accès réseau fiable.