OpenTelemetry s’est imposé comme le standard de l’observabilité — mais le plus dur reste à faire : l’exploiter vraiment
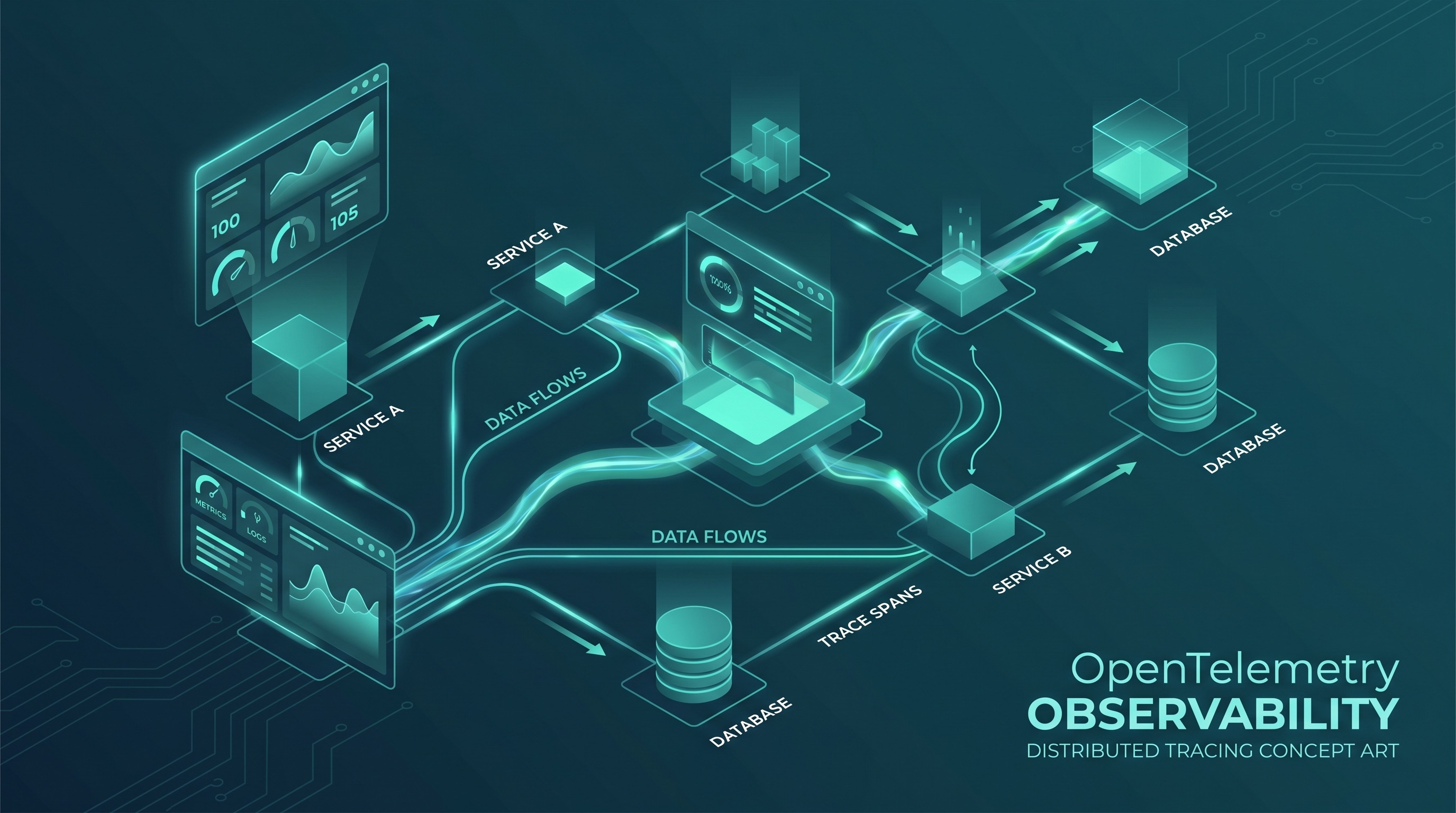
Il y a trois ans, les équipes d’ingénierie qui choisissaient une stack d’observabilité étaient confrontées à un choix douloureux : adopter les agents propriétaires d’un fournisseur et accepter un lock-in, ou assembler des outils open source disparates et en assumer la maintenance. OpenTelemetry — le projet CNCF né de la fusion d’OpenCensus et OpenTracing en 2019 — a largement résolu ce dilemme. En 2026, il est devenu le standard de facto pour la collecte de données de télémétrie dans toute l’industrie.
Datadog, Honeycomb, Grafana, New Relic, Dynatrace et Splunk acceptent tous nativement les données OpenTelemetry. Les fournisseurs cloud comme AWS, Google Cloud et Azure proposent une intégration native. Les SDK pour Python, Java, Go, JavaScript et .NET ont atteint des versions stables. Le Collector OpenTelemetry — le composant Pipeline qui reçoit, traite et exporte la télémétrie — est déployé en production dans des entreprises allant des petites startups aux hyperscalers.
OpenTelemetry a gagné la guerre de l’instrumentation. Le prochain défi est de savoir l’exploiter correctement.
Ce que OpenTelemetry standardise réellement
OpenTelemetry définit trois signaux de télémétrie : les traces (le chemin d’une requête à travers des services distribués), les métriques (mesures numériques dans le temps) et les logs (enregistrements structurés d’événements). Le projet fournit des SDK pour générer ces signaux, un format filaire (OTLP — OpenTelemetry Protocol) pour les transmettre, et le Collector pour les router vers les backends.
Ce qu’il ne standardise pas, c’est quoi faire des données une fois que vous les avez. Les langages de requête, les modèles d’alerting, les outils de dashboard et les workflows d’analyse sont tous spécifiques au backend. Passer de Datadog à Grafana nécessite toujours de réécrire les dashboards et les alertes — la couche de collecte des données est désormais portable, mais la couche d’analyse ne l’est pas. C’est le problème de « portabilité de l’observabilité » sur lequel l’industrie travaille encore.
Où les équipes se retrouvent bloquées
Le mode d’échec le plus courant est de considérer OpenTelemetry comme une case à cocher plutôt qu’une pratique. Les équipes instrumentent leurs services, voient des traces apparaître dans leur backend d’observabilité, et déclarent victoire. Six mois plus tard, lors d’un incident en production, elles découvrent que les traces sont incomplètes (certains services n’étaient pas instrumentés), que les spans manquent d’attributs utiles (pas d’IDs utilisateur, pas de feature flags, pas de contexte métier), et que la cardinalité de leurs métriques a explosé les limites de leur backend.
La qualité de l’instrumentation est le premier écart. L’auto-instrumentation — où le SDK génère automatiquement des spans pour les appels HTTP, les requêtes base de données et les opérations de file d’attente — capture le squelette structurel d’une requête mais rien de la logique métier. Savoir si un appel API était pour un client premium ou un client gratuit, quel feature flag était actif, quel était le total du panier : ce sont des attributs qui nécessitent une instrumentation manuelle. Les équipes qui tirent le meilleur parti d’OpenTelemetry sont celles qui traitent les attributs de spans comme un produit d’une conception délibérée plutôt que d’une génération automatique.
La cardinalité est le deuxième écart. Chaque combinaison unique de valeurs d’attributs crée une nouvelle série temporelle dans un backend de métriques. Une métrique taguée avec l’ID utilisateur, la région, le feature flag et le code statut HTTP peut créer des millions de séries distinctes — et de nombreux backends d’observabilité facturent par série temporelle ou imposent des limites strictes. Les équipes qui instrumentent des métriques sans réfléchir soigneusement à la cardinalité finissent soit par payer des factures d’observabilité étonnamment élevées, soit par atteindre des limites de perte de données exactement quand elles en ont le plus besoin.
Le Collector en tant qu’actif stratégique
Le Collector OpenTelemetry est sans doute le composant le plus sous-utilisé de l’écosystème. La plupart des équipes le déploient comme un simple forwarder — recevoir l’OTLP des services, exporter vers le backend. Le pipeline de processeurs du Collector peut faire bien plus : filtrer les données à haute cardinalité avant qu’elles n’atteignent le backend, échantillonner les traces selon des règles métier (échantillonner 100 % des traces d’erreur, 1 % des traces réussies), enrichir les spans avec des métadonnées provenant de Kubernetes ou de la découverte de services, et router différents signaux vers différents backends.
Un pipeline Collector bien configuré peut réduire les coûts d’observabilité de 60 à 80 % sans perdre de signal significatif, en supprimant agressivement les données de faible valeur (traces de health check, tâches de fond routinières) tout en préservant tout ce qui est pertinent pour le débogage et l’analyse métier. Les équipes qui considèrent le Collector comme une infrastructure à configurer soigneusement plutôt qu’à déployer et oublier tirent considérablement plus de valeur du même budget.
Conventions sémantiques : le standard sous-estimé
Les conventions sémantiques d’OpenTelemetry — une spécification pour nommer et structurer les attributs sur les spans et les métriques — sont la contribution la plus sous-estimée du projet. Quand chaque équipe nomme ses attributs de spans base de données différemment, vous ne pouvez pas écrire de dashboards ou d’alertes génériques qui fonctionnent pour tous les services. Quand tout le monde suit les mêmes conventions (db.system, db.statement, http.method, http.status_code), les outils peuvent raisonner sur la télémétrie sans configuration spécifique au service.
L’adoption des conventions sémantiques est encore incomplète en pratique. Les conventions stables couvrent HTTP, les bases de données, les systèmes de messagerie et RPC — les motifs d’infrastructure les plus courants. De nombreux motifs spécifiques aux applications ne sont pas couverts ou sont encore en statut expérimental. Les équipes qui construisent sur OpenTelemetry devraient investir du temps à définir leurs propres conventions d’attributs pour le contexte applicatif, en suivant les schémas de nommage établis par le projet, pour bénéficier des mêmes avantages de composabilité au niveau applicatif.
À quoi ressemble une bonne pratique en 2026
Les équipes qui tirent le plus de valeur d’OpenTelemetry en 2026 partagent quelques caractéristiques. Elles ont une équipe plateforme ou un champion de l’observabilité qui possède la configuration du Collector et les standards d’instrumentation. Elles ont défini un ensemble d’attributs de spans requis pour les nouveaux services et les imposent lors des revues de code. Elles ont réalisé une analyse explicite de la cardinalité sur leurs métriques et fait des choix délibérés sur les dimensions à conserver. Elles utilisent l’échantillonnage tail-based pour capturer des traces complètes pour les erreurs et les requêtes lentes tout en échantillonnant agressivement le trafic de routine.
Elles traitent également les données d’observabilité comme un produit, pas comme un rejet d’infrastructure. La question n’est pas « collectons-nous des données ? » mais « l’ingénieur d’astreinte peut-il trouver la cause racine d’un incident de production en moins de 10 minutes ? » Ce standard induit des décisions d’instrumentation différentes de « le Collector tourne-t-il ? »
OpenTelemetry a résolu le problème de coordination le plus difficile en observabilité : faire en sorte que l’industrie s’accorde sur un format de données commun. La prochaine couche de problèmes — quoi instrumenter, comment configurer le pipeline, quoi construire par-dessus — sont des défis techniques et organisationnels que chaque équipe doit résoudre par elle-même. La bonne nouvelle est que les fondations sont désormais assez stables pour construire dessus.