OpenTelemetry est désormais la norme en observabilité — voici ce que cela implique concrètement pour votre stack
OpenTelemetry a franchi en 2026 un seuil bien plus significatif que n'importe quel chiffre de téléchargement : il a cessé d'être un outil à évaluer pour devenir un héritage. Quand vous embauchez un nouveau développeur backend et qu'il vous demande quelle stack d'observabilité vous utilisez, OTel est la réponse attendue. Quand vous lancez un nouveau service et que vous cherchez à l'instrumenter, c'est vers OTel que vous vous tournez. Le projet CNCF né de la fusion d'OpenCensus et OpenTracing en 2019 a, sept ans plus tard, remporté la guerre des standards d'instrumentation.
Les chiffres appuient ce constat. Début 2026, 48,5% des organisations utilisent activement OpenTelemetry, et 25% supplémentaires prévoient de le faire. 81% le considèrent comme prêt pour la production. Le SDK Python à lui seul a enregistré 224 millions de téléchargements en janvier 2026, soit 6 millions par jour. Le rapport CNCF fait état d'une augmentation de 43% des commits et de 50% des pull requests fusionnées en 2025. OpenTelemetry n'est plus un outil de niche pour passionnés d'observabilité : c'est une infrastructure.
Ce qu'OTel standardise réellement — et ce qu'il ne standardise pas
OpenTelemetry standardise trois éléments : les API pour instrumenter le code (comment vous émettez les données de télémétrie), les SDK pour collecter et traiter ces données, et le protocole OTLP pour les transmettre à un backend. Ce qu'il ne standardise pas, c'est la destination des données ni ce que vous en faites une fois arrivées.
C'est là la distinction architecturale cruciale. OTel est un tuyau, pas une base de données ni une couche de visualisation. Vous pouvez envoyer les données OTel vers Grafana, Datadog, Honeycomb, Dynatrace, Elastic, Jaeger, Prometheus, ou tout backend qui parle OTLP — ce qui, en 2026, est essentiellement le cas de tous. L'augmentation de 36% en un an des distributions OTel provenant de fournisseurs (des éditeurs fournissant leurs propres collectors et SDK compatibles OTel) reflète l'adaptation du marché à cette réalité : si votre backend d'observabilité ne supporte pas nativement l'ingestion OTel, vous êtes désavantagé.
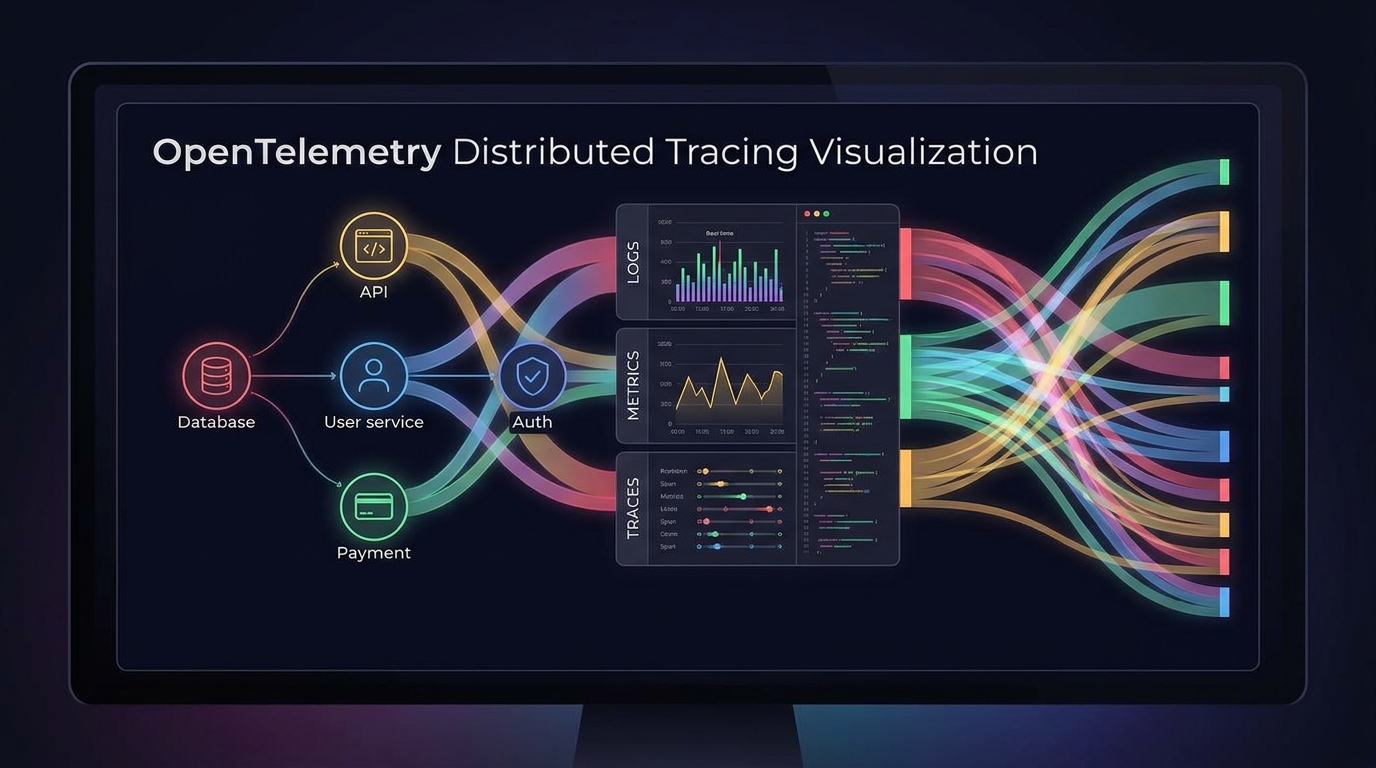
Les trois signaux de télémétrie couverts par OTel sont les traces (traces distribuées à travers le chemin d'une requête entre services), les métriques (mesures numériques dans le temps — latence, taux d'erreur, débit) et les logs (enregistrements d'événements structurés). En 2026, les traces sont les plus matures et les plus utilisées (50,2% des utilisateurs d'OTel), suivies des métriques (57%) et des logs (48,4%). Les profils — données de profiling continu — sont un quatrième signal émergent que 9,2% des utilisateurs instrumentent déjà, un indicateur précoce de l'extension du périmètre d'OTel.
Le Collector : là où réside la complexité de production
Le OpenTelemetry Collector est le composant qui effectue le traitement des données proprement dit : réception de la télémétrie depuis les services instrumentés, application de transformations et de filtrage, puis envoi vers un ou plusieurs backends. 65% des utilisateurs d'OTel en production exploitent plus de 10 Collectors ; les grands déploiements en comptent des centaines. Kubernetes reste l'environnement de déploiement dominant (81%), mais les déploiements sur VM ont fortement augmenté (de 33% à 51%), reflétant une adoption dans des environnements qui n'ont pas tout conteneurisé.
Le modèle de pipeline du Collector — récepteurs, processeurs, exportateurs enchaînés — offre une flexibilité à la fois puissante et opérationnellement complexe. Un schéma de production courant : un Collector sidecar par pod qui assure la collecte initiale et le filtrage de base, alimentant un cluster de Collectors passerelles qui appliquent l'échantillonnage, l'enrichissement et le routage avant envoi aux backends. Cette architecture à deux niveaux sépare les préoccupations d'instrumentation par service des préoccupations de traitement au niveau du cluster, ce qui compte à grande échelle.
Le problème opérationnel le plus fréquent dans les déploiements OTel à grande échelle est la gestion de la cardinalité. Les labels à haute cardinalité sur les métriques — utilisation d'identifiants utilisateur, d'identifiants de requête ou d'autres valeurs non bornées comme dimensions de labels de métriques — peuvent faire exploser le nombre de séries temporelles, créant des coûts mémoire et stockage qui rendent l'observabilité plus onéreuse que les systèmes observés. Les processeurs de filtrage et de transformation du Collector peuvent imposer des limites de cardinalité, mais cela nécessite une configuration délibérée que les équipes ne priorisent souvent pas avant d'avoir rencontré le problème.
Instrumentation : automatique vs manuelle
Les bibliothèques d'auto-instrumentation d'OTel couvrent la majorité des besoins d'instrumentation courants sans modification de code. Pour les applications Java, l'agent Java auto-instrumente les clients et serveurs HTTP, JDBC, gRPC, Kafka, Redis et des dizaines d'autres bibliothèques en s'attachant au niveau JVM. Pour Python, Node.js, .NET, Go et autres langages supportés, une auto-instrumentation similaire couvre les frameworks et bibliothèques utilisés par la plupart des applications.
L'auto-instrumentation apporte 80% de la valeur avec un effort minimal. Les 20% restants — instrumenter votre logique métier réelle, ajouter des attributs personnalisés porteurs de contexte de domaine, créer des spans pour des opérations qui ne correspondent pas à des appels de bibliothèque — nécessitent une instrumentation manuelle via l'API OTel. Les disciplines sont différentes : l'auto-instrumentation est un problème de configuration de déploiement, l'instrumentation manuelle est un problème de qualité de code et de compréhension architecturale.
Les cibles d'instrumentation manuelle à plus forte valeur ajoutée ne consistent pas à « ajouter des spans partout » — elles sont spécifiques à ce qui rend le comportement de votre système observable à des fins de débogage. Quelles sont les opérations dont vous devez comprendre la distribution de latence ? Quels sont les attributs au niveau domaine (tier client, valeurs de feature flags, identifiants de ressources) que vous devez corréler entre services lors de l'investigation d'un incident ? Une instrumentation manuelle qui répond à ces questions vaut bien plus qu'une couverture uniforme de tout.
L'échantillonnage : la tension non résolue
Traquer chaque requête dans les moindres détails dans un système de production à fort volume est économiquement irréaliste. Un service traitant 10 000 requêtes par seconde génère des volumes de traces énormes si chaque requête produit une trace complète. L'échantillonnage (Sampling) — n'enregistrer qu'une fraction des traces — est une nécessité pratique, mais il crée une tension fondamentale : les traces dont vous avez le plus besoin pour le débogage (chemins d'erreur, outliers lents, séquences inhabituelles) sont exactement celles que vous risquez le plus de manquer si vous échantillonnez naïvement.
L'échantillonnage en tête (Head-based sampling, décider au début de la requête si on la trace) est simple à implémenter mais aveugle aux résultats — vous ne pouvez pas savoir si une requête sera intéressante tant qu'elle n'est pas terminée. L'échantillonnage en queue (Tail-based sampling, décider après coup, en conservant les traces qui répondent à des critères comme la présence d'erreur ou un seuil de latence) est plus intelligent mais nécessite de mettre en tampon les traces complètes avant de prendre la décision, ce qui ajoute de la latence et une surcharge mémoire au Collector.
Le Tail Sampling Processor d'OTel implémente l'échantillonnage en queue dans le Collector, et il est disponible en production. La configuration n'est pas triviale : vous devez définir des politiques (conserver toutes les erreurs, conserver les requêtes dépassant X millisecondes, conserver un échantillon aléatoire de base de tout le reste) et ajuster la taille des tampons. Les équipes qui investissent dans la configuration de l'échantillonnage en queue obtiennent un rapport signal/bruit nettement meilleur sur leurs traces. Celles qui utilisent un échantillonnage en tête avec un taux fixe obtiennent une couverture suffisante pour la plupart des usages, mais manquent la longue traîne des événements intéressants.
Où va OTel : les profils et au-delà
La CNCF envisage d'accorder le statut de projet Graduated à OpenTelemetry en 2026 — la plus haute maturité dans le cycle de vie CNCF, actuellement détenue par des projets comme Kubernetes, Prometheus et Envoy. L'obtention de ce statut signalerait que le projet est stable, largement déployé, et a démontré la maturité de gouvernance nécessaire pour être considéré comme une infrastructure fondamentale.
La prochaine frontière fonctionnelle est le profiling continu — le quatrième signal de télémétrie qu'OpenTelemetry étend. Le profiling continu capture les données au niveau CPU, mémoire et goroutine/thread des processus en cours d'exécution de manière récurrente, permettant de corréler les performances au niveau des traces avec le code réel exécuté pendant les requêtes lentes. Corréler une trace lente avec un profil CPU qui montre quelle fonction brûlait des cycles pendant cette fenêtre de requête est exactement le type d'analyse multi-signaux que le modèle de données unifié d'OTel rend possible.
Si vous n'utilisez pas OTel en 2026, vous n'êtes pas en retard sur une courbe technologique — vous êtes en retard sur un standard industriel. La phase d'évaluation est terminée. La question est désormais de savoir comment instrumenter, collecter et router vos données de télémétrie en utilisant des outils qui, largement, ont convergé vers OTel comme fondation.