SQLite : la base de données que le cloud n’avait pas vue venir — et qui s’impose quand même
Il y a environ 1 billion de déploiements actifs de SQLite dans le monde. Ce chiffre, tiré de la documentation officielle du projet SQLite, n’est pas une estimation marketing — c’est une réalité architecturale. Chaque iPhone embarque SQLite. Chaque appareil Android l’utilise. Firefox s’en sert pour l’historique, les marque-pages et les cookies. Chrome l’utilise pour son backend de base de données. Skype, Dropbox, iTunes, VLC et l’intégralité de la suite Adobe Creative l’intègrent. La Bibliothèque du Congrès américain le recommande comme format d’archivage. SQLite est, par nombre de déploiements, le moteur de base de données le plus utilisé au monde — et jusqu’à récemment, la plupart des développeurs le voyaient simplement comme un composant embarqué dans les applications mobiles, pas comme une infrastructure sérieuse.
Ce cadre de pensée est désormais obsolète. En 2026, SQLite tourne dans le réseau global edge de Cloudflare, alimente des applications distribuées via le fork libSQL de Turso et constitue le fondement d’une architecture d’application local-first qui attire l’attention sérieuse des ingénieurs. La base de données qu’on a qualifiée pendant trente ans de « pas pour la production » redéfinit tranquillement ce que production signifie.
Ce qu’est vraiment SQLite
SQLite est une bibliothèque C — environ 155 000 lignes — qui implémente un moteur SQL complet dans un seul fichier, sans dépendances externes, sans processus serveur et sans configuration. Une base de données n’est qu’un fichier sur disque. L’ouvrir ne nécessite ni chaîne de connexion, ni handshake d’authentification, ni daemon à contacter. Vous liez la bibliothèque, ouvrez le fichier et exécutez du SQL. C’est tout le paramétrage.
Malgré sa simplicité, SQLite est entièrement conforme ACID. Les écritures sont atomiques ; les lectures concurrentes sont supportées via son mode WAL (Write-Ahead Log) ; le format sur disque est stable et totalement rétrocompatible depuis 2004. Il prend en charge la norme SQL-92 complète ainsi que la majeure partie de SQL:1999, y compris les fonctions de fenêtrage, les CTE et les opérateurs JSON ajoutés dans les versions récentes. Le projet est maintenu par une petite équipe sous dédicace au domaine public — pas de licence, pas de copyright, pas d’accords de contributeurs.
Richard Hipp l’a lancé en 2000 pour le programme de destroyers lance-missiles de la marine américaine, où l’absence d’administrateur de base de données était une contrainte de conception, pas un oubli. Cette origine définit tout ce qu’est SQLite : il a été conçu pour des environnements où l’on ne peut pas se permettre un serveur, un DBA ou une connectivité réseau. Ces contraintes, il s’avère, décrivent presque parfaitement l’environnement de l’edge computing.
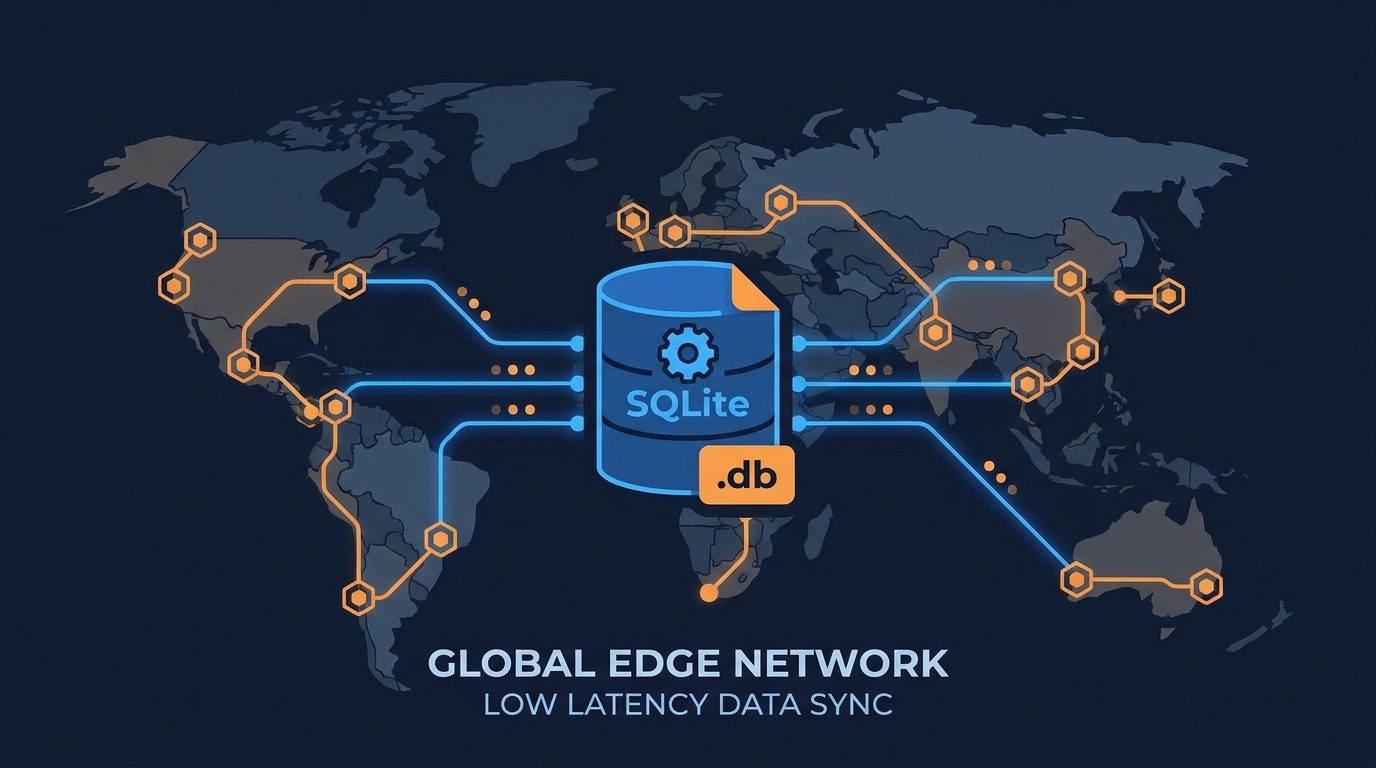
SQLite à l’edge : Cloudflare D1, Turso et LiteFS
Cloudflare D1, lancé en disponibilité générale en 2023 et considérablement étendu en 2024‑2025, est SQLite qui tourne dans Cloudflare Workers sur plus de 300 sites edge dans le monde. Lorsqu’un Worker exécute une requête D1, il lit un fichier SQLite co-localisé sur le nœud edge le plus proche de l’utilisateur. Les lectures sont inférieures à la milliseconde. La base de données peut atteindre 10 Go par base sans provisionnement — vous créez une base D1 avec une seule commande CLI et elle est immédiatement disponible globalement.
D1 résout le problème des écritures via un modèle primaire‑réplica : les écritures vont vers un emplacement primaire et sont répliquées de manière asynchrone vers tous les nœuds edge. Pour les charges de travail à forte lecture — ce qui décrit la plupart des applications web — l’avantage en latence par rapport à une instance PostgreSQL monorégion est conséquent. Cloudflare rapporte que D1 sert plus de 50 milliards de lignes lues par mois sur l’ensemble de sa clientèle début 2026.
Turso, construit sur libSQL — un fork open source de SQLite maintenu par ChiselStrike — adopte une approche architecturale différente. libSQL étend SQLite avec la réplication native, le mode serveur et le support d’API HTTP, tout en restant compatible au niveau fichier avec le SQLite standard. Turso propose des réplicas embarqués : votre application exécute un réplica SQLite local qui se synchronise avec une base de données centrale, vous offrant des lectures locales à latence zéro et une cohérence éventuelle sur les écritures. Le modèle est explicitement conçu pour les runtimes edge et les fonctions serverless où le coût de latence d’un appel distant à une base de données est prohibitif.
LiteFS, développé par Ben Johnson et désormais maintenu sous l’égide de Fly.io, adopte une approche FUSE pour la réplication de SQLite. Il intercepte les écritures au niveau du système de fichiers et réplique le write-ahead log de SQLite vers d’autres nœuds via une couche de consensus. Les applications ne nécessitent aucune modification de code — LiteFS se place entre l’application et le système de fichiers, synchronisant de manière transparente les bases SQLite au sein d’un cluster Fly.io. Fly.io Volumes, la couche de stockage persistant pour les apps Fly, combinée à LiteFS, offre aux développeurs une configuration SQLite distribuée avec basculement automatique et réplication sur plusieurs régions.
SQLite-over-HTTP et les nouveaux schémas d’accès
L’un des développements les plus intéressants de l’écosystème SQLite est l’émergence de couches d’accès HTTP qui lui permettent de se comporter davantage comme une base de données client‑serveur classique sans perdre ses avantages embarqués. Le mode serveur de libSQL expose une API WebSocket et HTTP à laquelle les clients peuvent se connecter à distance — ce qui signifie qu’une base SQLite tournant sur un serveur peut être interrogée depuis un navigateur, une app mobile ou une fonction serverless en utilisant la sémantique HTTP standard.
Cela compte car cela ouvre SQLite à des environnements où il est impossible d’intégrer directement la bibliothèque. Une application Next.js déployée sur Vercel ne peut pas embarquer une bibliothèque SQLite native — mais elle peut envoyer des requêtes HTTP à une base Turso et obtenir des résultats SQL au format JSON. L’expérience développeur est quasi identique à une requête Postgres via un pool de connexions, mais le moteur sous‑jacent est SQLite, avec toute la simplicité opérationnelle que cela implique.
Bun, le runtime JavaScript qui gagne du terrain comme alternative plus rapide à Node.js, intègre le support natif de SQLite via son module bun:sqlite — pas de npm install nécessaire, pas de compilation de module natif, pas de node-gyp. const db = new Database("mydb.sqlite"); : tout le paramétrage tient en une ligne. Les performances que Bun cite pour son implémentation SQLite — plus de 4 millions de lectures par seconde sur un portable — reflètent la rapidité d’une base de données sans surcharge réseau lorsqu’elle tourne dans le même processus que votre code applicatif.
Architecture local-first et l’essor des CRDTs
Le mouvement local-first dans le développement web repose sur une affirmation spécifique : la bonne architecture pour la plupart des applications est celle où la base de données réside sur le client, les lectures sont instantanées car elles accèdent au stockage local, et la synchronisation avec un serveur se fait en arrière-plan. L’expérience utilisateur est plus rapide, la fonctionnalité hors ligne est intégrée, et le serveur devient un relais de synchronisation plutôt qu’un goulot d’étranglement de requêtes.
SQLite s’intègre naturellement à cette architecture car il fonctionne partout — dans le navigateur via WebAssembly (wa-sqlite, sql.js), dans les apps Electron de manière native, sur mobile via le SQLite intégré de la plateforme, et sur les nœuds edge via D1 ou Turso. Les mêmes requêtes SQL fonctionnent dans tous ces environnements sur des fichiers fondamentalement compatibles entre eux.
Le problème difficile dans une architecture local-first est la résolution de conflits : si deux clients écrivent tous deux dans un réplica SQLite local alors qu’ils sont hors ligne, comment fusionner ces écritures lorsqu’ils se reconnectent ? C’est là que les CRDT (Conflict-free Replicated Data Types) entrent en jeu. cr-sqlite, une extension SQLite développée par Matt Wonlaw chez Vlcn.io, implémente la sémantique CRDT directement dans SQLite en instrumentant les tables SQL standard avec une horloge Lamport et une fonction de fusion. Deux bases cr-sqlite peuvent être fusionnées de manière déterministe sans autorité centrale. Tout conflit au niveau des lignes est résolu par les règles de fusion CRDT, et non par un serveur qui décide quelle écriture l’emporte.
Cette combinaison — SQLite pour le stockage, CRDT pour la sémantique de fusion, un relais de synchronisation pour la connectivité — est l’architecture derrière des outils comme ElectricSQL, Replicache et Zero (de l’équipe Rocicorp qui a construit Replicache). Ce n’est plus purement expérimental : Linear, l’outil de gestion de projet, utilise une architecture local‑first basée sur SQLite pour son application de bureau, et attribue sa réactivité au fait que chaque interaction accède à une base locale plutôt qu’à une API distante.
Outillage développeur en 2026
L’écosystème ORM et d’outillage a rattrapé le rôle élargi de SQLite. Drizzle ORM, l’un des ORM TypeScript à la croissance la plus rapide, traite SQLite comme une cible de première classe aux côtés de PostgreSQL et MySQL — avec des adaptateurs spécifiques pour better-sqlite3, le SQLite natif de Bun, libSQL, D1 et Turso. L’inférence de types de Drizzle fait en sorte que votre schéma SQLite pilote vos types TypeScript sans surcharge à l’exécution.
Prisma a ajouté le support de D1 en 2024 avec son modèle d’adaptateurs de pilote, permettant au moteur de requêtes de Prisma de fonctionner avec Cloudflare D1 via l’API HTTP de D1. La définition du schéma Prisma reste identique que vous cibliez Postgres ou D1 ; seule l’initialisation du client change. better-sqlite3, la liaison Node.js pour SQLite par Joshua Wise, reste la référence pour un accès SQLite synchrone et performant dans Node.js côté serveur — son API synchrone est un choix délibéré, correspondant à la nature synchrone de SQLite et évitant la surcharge async qui affecte la plupart des pilotes de base de données.
Où SQLite montre vraiment ses limites
Le modèle à un seul écrivain de SQLite est sa contrainte architecturale la plus significative. Une seule transaction d’écriture peut s’exécuter à la fois — même en mode WAL, qui permet des lectures concurrentes en parallèle d’un unique écrivain, vous ne pouvez pas avoir deux processus écrivant simultanément dans la même base SQLite sans sérialisation. Pour les applications à fort débit d’écriture concurrente — un classement recevant des milliers de mises à jour de score par seconde, un système de messagerie avec des écritures simultanées de milliers de clients connectés — le modèle d’écriture de SQLite est un mur infranchissable.
Le mode WAL aide considérablement pour les charges de travail à forte lecture avec des écritures occasionnelles : les lecteurs ne bloquent jamais les écrivains et les écrivains ne bloquent jamais les lecteurs. Mais WAL ne change pas la contrainte fondamentale d’un seul écrivain. Si votre goulot d’étranglement est la concurrence en écriture, vous avez besoin d’une base de données avec un gestionnaire de verrous conçu pour cela — PostgreSQL, MySQL ou un système distribué comme CockroachDB.
Il n’y a pas non plus de réplication intégrée. Le SQLite standard n’a pas de concept de primaire/réplica, pas de livraison de WAL, pas de slots de réplication logique. Chaque solution de réplication dans l’écosystème — LiteFS, les réplicas embarqués de Turso, cr-sqlite — est une couche construite par des tiers au-dessus de SQLite. Cela signifie que les configurations de réplication comportent une complexité opérationnelle plus grande qu’il n’y paraît : vous gérez deux systèmes (SQLite plus la couche de réplication) plutôt qu’un seul. Et les garanties de cohérence varient : les réplicas embarqués de Turso sont en cohérence éventuelle, pas en cohérence forte — une écriture sur un réplica peut ne pas être immédiatement visible sur un autre.
La taille du fichier de base de données devient également une considération à grande échelle. SQLite manipule couramment des bases de données de plusieurs dizaines de gigaoctets et a été testé jusqu’à des centaines de gigaoctets, mais à cette échelle, une partie de la simplicité opérationnelle qui rend SQLite attractif se perd. Déplacer un fichier SQLite de 50 Go à des fins de sauvegarde est une proposition différente que de le répliquer via un flux basé sur un log.
Quand choisir SQLite, et quand ne pas le faire
SQLite est le bon choix lorsque votre ratio lectures/écritures est élevé, lorsque vous voulez une charge opérationnelle nulle, lorsque vous construisez pour l’edge ou pour des architectures local‑first, ou lorsque vous livrez un outil développeur, un CLI ou une application embarquée où un serveur de base de données serait absurde. D1 et Turso l’ont rendu viable pour des applications web de production avec des utilisateurs globaux, à condition que ces applications soient à forte lecture et puissent tolérer une cohérence éventuelle sur les écritures.
PostgreSQL reste le bon choix lorsque vous avez besoin d’une forte concurrence en écriture, de verrouillage au niveau ligne, de topologies de réplication complexes ou de l’écosystème d’extensions profond (PostGIS, pgvector, TimescaleDB) que Postgres a construit en trente ans. MySQL et MariaDB occupent un territoire similaire. Une base de données distribuée comme CockroachDB ou PlanetScale est justifiée lorsque vous avez besoin d’une mise à l’échelle horizontale des écritures avec des garanties de cohérence forte entre régions — un cas d’usage pour lequel SQLite n’a jamais été conçu.
La question la plus intéressante pour 2026 n’est pas « SQLite vs. Postgres » mais « quelle est la place de chacun dans un même système ? » De nombreuses architectures de production utilisent désormais les deux : SQLite à l’edge pour les données spécifiques à l’utilisateur, à faible écriture (état de session, préférences, flux personnalisés) et Postgres au centre pour les données partagées à forte écriture (transactions, inventaire, messagerie). La base de données que le cloud n’attendait pas a trouvé sa place dans la stack — non pas en remplaçant ce qui existait avant, mais en gérant les cas où lancer un cluster Postgres a toujours été la mauvaise réponse.