Un paquet PyPI empoisonné a compromis la start-up d’entraînement IA Mercor — et exposé 4 To de données de sous-traitants à Lapsus$
Le 31 mars 2026, Mercor — une start-up de 10 milliards de dollars qui fournit des services d’étiquetage de données IA, d’annotation et de gestion de sous-traitants à OpenAI, Anthropic, Meta et Google — a confirmé une brèche que les chercheurs en sécurité qualifient de l’une des attaques les plus significatives sur la chaîne d’approvisionnement jamais menées contre l’industrie de l’IA à ce jour. Environ 4 To de données ont été exfiltrées : 939 Go de code source de la plateforme, 211 Go d’enregistrements de bases de données utilisateurs, et environ 3 To de contenus de buckets de stockage comprenant des scans de passeports de sous-traitants, des numéros de Sécurité sociale, des documents de vérification d’identité et des enregistrements vidéo d’entretiens techniques. Le groupe revendiquant la responsabilité est Lapsus$, qui a mis les données volées aux enchères sur son marché du dark web. Cinq recours collectifs ont déjà été déposés contre Mercor par des sous-traitants concernés.
La chaîne d’attaque : trois sauts du scanner à la production
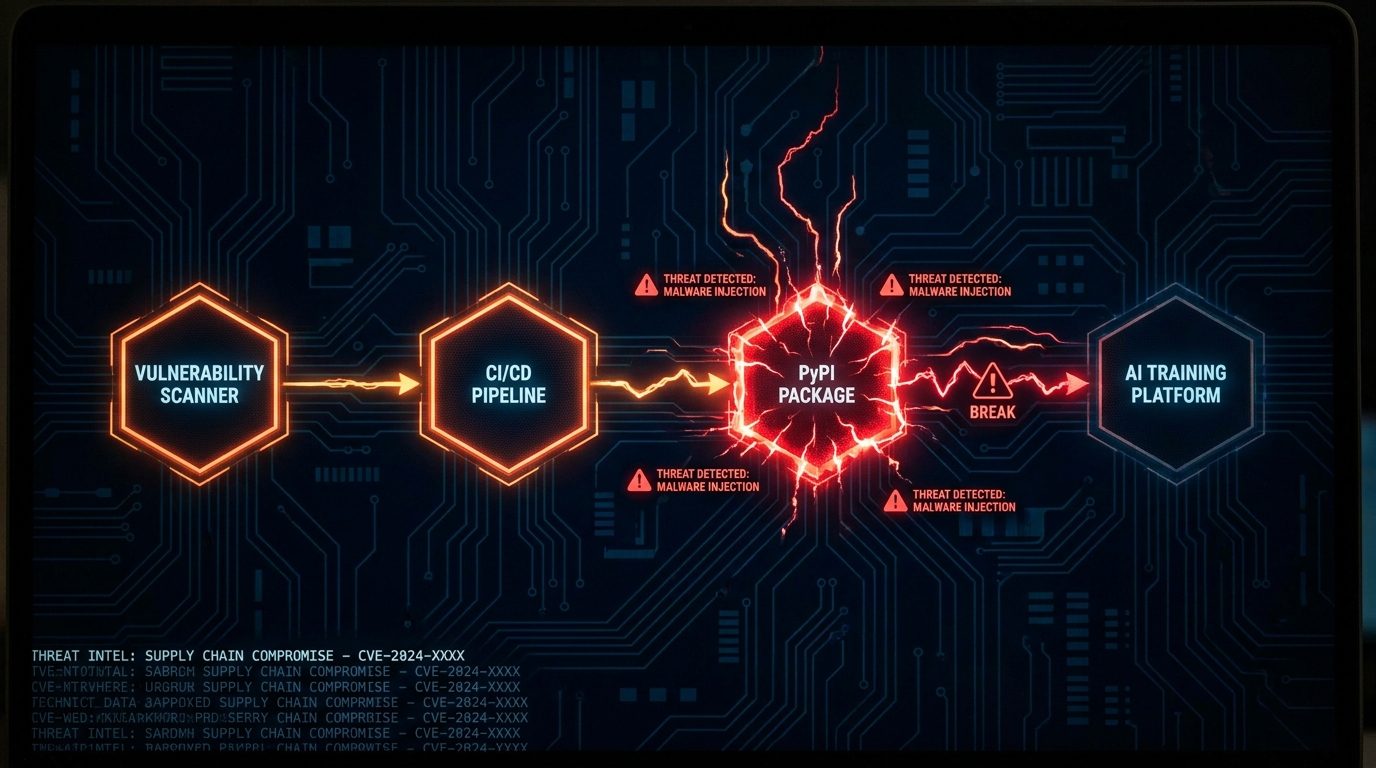
Ce qui rend cette brèche techniquement distinctive, c’est le chemin d’attaque. Il ne s’agissait pas d’une intrusion directe dans les systèmes de Mercor. C’était une attaque de la chaîne d’approvisionnement en trois étapes qui a traversé l’écosystème des outils open source avant d’atteindre un environnement de production.
Saut 1 — 19 mars : Trivy est compromis. Trivy est un scanner de vulnérabilités open source largement utilisé, maintenu par Aqua Security et intégré dans les pipelines CI/CD de milliers d’organisations. Le groupe d’attaquants, opérant sous le nom TeamPCP, a obtenu un accès en écriture aux artefacts de release de Trivy. Le vecteur initial exact dans Trivy n’a pas été divulgué publiquement, mais le résultat est que TeamPCP avait la capacité d’influencer ce que Trivy exécutait lors de ses scans.
Saut 2 : Extraction d’identifiants CI/CD depuis LiteLLM. LiteLLM — une bibliothèque Python open source populaire qui fournit une passerelle d’API unifiée pour appeler différents fournisseurs de modèles de langage de grande taille — utilisait Trivy dans le cadre de son pipeline CI/CD automatisé pour scanner les conteneurs et les dépendances à la recherche de vulnérabilités connues. De manière critique, la configuration CI/CD de LiteLLM ne verrouillait pas Trivy sur un hash de version spécifique. Elle tirait Trivy sans verrouillage de version, ce qui signifie que lorsque le Trivy compromis s’exécutait dans l’environnement de build de LiteLLM, il avait accès aux secrets du pipeline : identifiants de publication PyPI, tokens de dépôt et variables d’environnement. TeamPCP a extrait ces identifiants via le scanner compromis lors d’un build de routine.
Saut 3 — 27 mars : Versions malveillantes de LiteLLM sur PyPI. Armé des identifiants de publication PyPI de LiteLLM, TeamPCP a poussé deux releases malveillantes : litellm==1.82.7 et litellm==1.82.8. Les paquets étaient fonctionnellement identiques aux releases légitimes dans leur comportement de surface — ils passaient les tests d’import de base et pouvaient router les appels API LLM normalement. La charge utile injectée s’exécutait à l’import ou à la première utilisation, établissant une connectivité sortante et exfiltrant les variables d’environnement, les clés d’API et les chemins du système de fichiers accessibles au processus en cours. Toute organisation tirant ces versions dans un environnement de production — via pip install litellm sans verrouillage de version, ou via l’automatisation de mise à jour des dépendances — exécutait du code contrôlé par l’attaquant.
Mercor a été l’une de ces organisations. Étant donné que LiteLLM est utilisé dans tout l’écosystème de développement IA comme infrastructure pour construire des applications qui appellent GPT-4, Claude, Gemini et d’autres modèles, la fenêtre d’exposition était large. La plateforme de Mercor, qui gère les workflows des sous-traitants, stocke leurs documents d’identité et traite les données d’entraînement propriétaires pour les grands laboratoires d’IA, était une cible de grande valeur dans cette fenêtre.
Ce qui a été volé
Les données exfiltrées de Mercor se répartissent en trois catégories, chacune avec des profils de risque distincts :
- 939 Go de code source de la plateforme. Cela inclut le système de gestion des sous-traitants de Mercor, les outils d’évaluation et les interfaces par lesquelles les sous-traitants interagissent avec les tâches d’entraînement IA. Pour les clients de Mercor — OpenAI, Anthropic, Meta, Google — l’exposition de ce code révèle potentiellement comment leurs pipelines d’entraînement sont structurés au niveau de l’interface sous-traitant, quels types de tâches sont routés via Mercor, et quels mécanismes de contrôle qualité sont en place.
- 211 Go d’enregistrements de bases de données utilisateurs. Cela inclut les profils des sous-traitants, les métadonnées de compte, les enregistrements de paiement et la correspondance interne. Le schéma exact n’a pas été confirmé, mais étant donné les exigences de conformité de Mercor pour l’onboarding des sous-traitants, la base de données contient très probablement des informations personnellement identifiables pour des dizaines de milliers de sous-traitants.
- ~3 To de contenus de buckets de stockage. C’est la catégorie la plus sensible pour les sous-traitants individuels. Les buckets de stockage contenaient des enregistrements vidéo d’entretiens techniques utilisés pour la vérification d’identité et le filtrage des compétences, des scans de papiers d’identité délivrés par le gouvernement, y compris des passeports et des cartes d’identité nationales, des numéros de Sécurité sociale collectés lors de l’onboarding des sous-traitants américains, et des documents de vérification d’identité soumis pour satisfaire aux exigences KYC. La combinaison de vidéo biométrique, de pièce d’identité gouvernementale et de numéro de Sécurité sociale représente un package d’identité complet pour les sous-traitants concernés — suffisant pour le vol d’identité, la fraude à l’identité synthétique et l’ingénierie sociale ciblée.
Pourquoi les chaînes d’approvisionnement d’entraînement IA sont une cible particulièrement sensible
Une brèche d’une plateforme SaaS standard de gestion de sous-traitants serait grave principalement pour l’exposition des données personnelles. La brèche de Mercor est catégoriquement différente en raison de ce que les sous-traitants travaillant via Mercor manipulent réellement.
Les sous-traitants IA au niveau de la clientèle de Mercor ne font pas de la saisie de données générique. Ils effectuent des tâches qui touchent aux aspects les plus propriétaires et les plus sensibles sur le plan concurrentiel du développement de l’IA : évaluer les sorties des modèles sur des benchmarks de capacité qui n’ont pas été rendus publics, annoter des cas limites qui révèlent où un modèle échoue actuellement, noter les réponses selon des critères qui encodent la méthodologie d’entraînement RLHF d’une entreprise, et tester les filtres de sécurité d’une manière qui expose ce que le modèle peut et ne peut pas faire. Les instructions, les grilles d’évaluation et les spécifications de tâches que reçoivent les sous-traitants sont le noyau intellectuel de la manière dont ces laboratoires entraînent et alignent leurs modèles.
Le code source de Mercor — qui inclut les interfaces et les outils par lesquels ces tâches sont délivrées — pourrait exposer ces méthodologies même si les données des tâches individuelles elles-mêmes ne faisaient pas partie de l’ensemble exfiltré. Pour un adversaire construisant un modèle concurrent, ou pour un acteur étatique tentant de comprendre les limites de sécurité et les techniques d’entraînement des systèmes d’IA de pointe, cela représente un accès à des informations qui ne peuvent pas être reconstituées à partir de la recherche publique.
Réactions en aval
La réaction des clients de Mercor a été mesurée mais significative. Meta a suspendu indéfiniment tout travail de données routé via Mercor le 2 avril, deux jours après la confirmation de la brèche, citant l’incertitude quant à l’intégrité de l’environnement des sous-traitants et l’exposition potentielle des spécifications de tâches. OpenAI et Anthropic ont tous deux publié des déclarations confirmant qu’ils auditaient leur exposition — en examinant spécifiquement si des données d’entraînement propriétaires, des grilles d’annotation ou des cadres d’évaluation étaient accessibles aux sous-traitants via la plateforme désormais compromise de Mercor au moment de la brèche.
Ni OpenAI ni Anthropic n’ont confirmé si des matériaux d’entraînement propriétaires se trouvaient dans les données exfiltrées. Le dump de code source de 939 Go est le vecteur le plus probable d’exposition indirecte : si le code source de la plateforme de Mercor inclut des modèles de tâches intégrés, des critères d’évaluation ou des échantillons de sortie de modèle utilisés pour former la qualité des sous-traitants, ceux-ci seraient désormais en possession de Lapsus$.
Lapsus$ a mis l’ensemble des données de 4 To aux enchères sur son marché du dark web, avec ce que les sources décrivent comme un prix demandé à sept chiffres. Le groupe a un historique documenté de ventes de données — notamment avec les données volées à Nvidia, Samsung et Microsoft en 2022 — ce qui donne à l’annonce de l’enchère une crédibilité au-delà d’une simple menace d’extorsion.
Cinq recours collectifs ont été déposés devant les tribunaux fédéraux américains par des sous-traitants concernés, alléguant des pratiques de sécurité des données négligentes, l’absence de contrôles adéquats sur la chaîne d’approvisionnement et une notification insuffisante après la brèche. Les recours nomment spécifiquement Mercor ; aucun n’a encore nommé les entreprises d’IA dont les programmes de sous-traitance étaient hébergés sur la plateforme.
Ce que les développeurs devraient faire
Si votre codebase utilise LiteLLM, les mesures immédiates sont spécifiques :
- Vérifiez votre version installée. Exécutez
pip show litellmou inspectez votrerequirements.txt,pyproject.tomlou fichier de verrouillage. Si vous avezlitellm==1.82.7oulitellm==1.82.8quelque part dans votre graphe de dépendances — y compris les dépendances transitives — traitez l’environnement comme compromis. Faites tourner tous les secrets accessibles à ce processus : clés d’API, identifiants de base de données, tokens de fournisseur cloud et toutes les variables d’environnement. - Auditez votre stratégie de verrouillage des dépendances PyPI. Toute dépendance tirée avec une plage de versions (
litellm>=1.82) ou sans contrainte de version du tout (litellm) était vulnérable à ce type d’attaque. Verrouillez sur des versions exactes et utilisez un fichier de verrouillage (lepoetry.lockde Poetry ou lerequirements.txtgénéré parpip-compile) qui inclut des hachages. Le drapeau--require-hashesdans pip rend impossible l’installation d’un paquet dont le contenu ne correspond pas au hachage enregistré, même si un attaquant remplace une version sur PyPI. - Révisez le verrouillage de version de vos outils CI/CD. La brèche de LiteLLM est née du fait que Trivy n’était pas verrouillé sur une version spécifique dans le pipeline de build de LiteLLM. Chaque outil de votre pipeline CI/CD — scanners, linters, outils de build, exécuteurs de tests — devrait être verrouillé sur une version spécifique et idéalement sur un hachage de contenu. GitHub Actions permet de verrouiller les actions sur un SHA de commit complet plutôt que sur un tag, ce qui empêche les attaques par mutation de tag. Pour les outils basés sur des conteneurs comme Trivy, verrouillez sur le digest de l’image (
aquasec/trivy@sha256:...), pas sur le tag (aquasec/trivy:latest). - Auditez les secrets accessibles dans votre environnement de build. Les identifiants de publication PyPI ne devraient jamais être disponibles comme variables d’environnement dans la même étape de pipeline qui exécute le scan des dépendances ou les tests. Utilisez des jobs de pipeline séparés avec des périmètres d’identifiants distincts, et appliquez les principes de moindre privilège aux secrets que chaque étape peut accéder.
Le schéma : les attaques sur la chaîne d’approvisionnement contre les outils des développeurs
L’attaque LiteLLM est la plus récente d’une séquence d’attaques sur la chaîne d’approvisionnement qui ont progressivement ciblé des couches plus profondes de la pile d’outils des développeurs :
- SolarWinds (décembre 2020) : Des acteurs étatiques (APT29/Cozy Bear) ont compromis le système de build de SolarWinds, injectant une backdoor dans la plateforme Orion distribuée à environ 18 000 organisations, y compris des agences fédérales américaines. Le vecteur d’attaque était le pipeline de build lui-même.
- Codecov (avril 2021) : Les attaquants ont modifié le script bash uploader de Codecov hébergé sur sa propre infrastructure. Tout pipeline CI/CD qui exécutait le script — un motif courant pour le reporting de couverture de code — téléchargeait les variables d’environnement, y compris les secrets, vers des serveurs contrôlés par l’attaquant.
- xz Utils (mars 2024) : Une campagne d’ingénierie sociale sophistiquée de plusieurs années a abouti à l’intégration d’une backdoor dans la bibliothèque de compression xz, ciblant l’authentification du serveur SSH sur les systèmes Linux. L’attaquant a passé deux ans à gagner la confiance en tant que contributeur légitime avant d’insérer le code malveillant.
- LiteLLM via Trivy (mars 2026) : Un scanner de vulnérabilités utilisé sans verrouillage de version est devenu le point d’entrée pour le vol d’identifiants, ce qui a ensuite permis la publication d’un paquet malveillant sur PyPI sous le nom d’une bibliothèque de confiance.
Le fil conducteur est cohérent : les attaquants ne brisent pas des défenses applicatives durcies. Ils exploitent les relations de confiance entre les outils sur lesquels les développeurs comptent pour construire, tester et déployer des logiciels. Alors que les outils de développement IA deviennent plus interconnectés — avec des bibliothèques comme LiteLLM servant d’infrastructure critique pour router les appels vers les modèles de pointe — le rayon d’explosion d’une seule dépendance compromise augmente proportionnellement. La brèche de Mercor n’est pas une exception. C’est une illustration de ce à quoi ressembleront les prochaines années d’attaques sur la chaîne d’approvisionnement contre l’industrie de l’IA.
Originally reported by Security Boulevard. Read the original article for additional details.
View original source