Fine-tuning vs. RAG: Qual Abordagem Realmente Funciona para IA Corporativa em 2026
RAG Vence a Maioria das Batalhas Empresariais — Mas o Fine-tuning Ainda Tem Seu Papel
Para a grande maioria dos casos de uso empresarial de IA em 2026, a Geração Aumentada por Recuperação (RAG) oferece um ROI melhor do que o fine-tuning de um modelo base. Isso não é discurso de vendedor — é a conclusão a que se chega ao analisar o custo total de propriedade, a latência de atualização e os benchmarks de precisão em implantações reais. O fine-tuning continua sendo a escolha certa em um conjunto restrito, mas importante, de cenários: adaptação a domínios altamente especializados, inferência de borda com restrição de latência e tarefas de consistência de estilo/formato onde nenhuma recuperação externa é aceitável.
Este post detalha exatamente o porquê, com números. Se você é um engenheiro de IA decidindo entre as duas abordagens para uma base de conhecimento interna, um copiloto voltado para o cliente ou um classificador específico de domínio, aqui está o framework que economizará meses de iteração cara.
O Que Cada Abordagem Realmente Faz (Além do Básico)
Você conhece as definições teóricas. O que importa na prática é entender os modos de falha de cada uma.
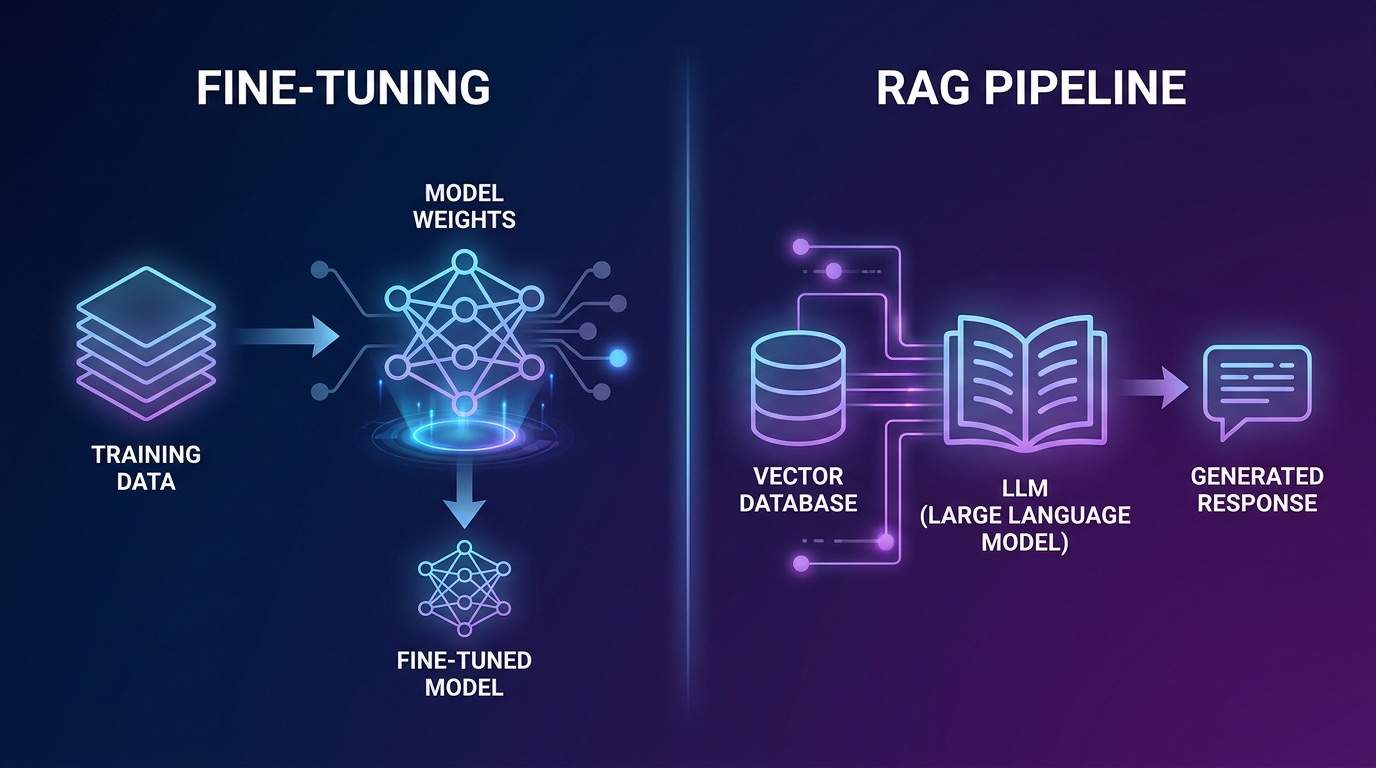
Fine-tuning em Produção
O fine-tuning ajusta os pesos do modelo usando um conjunto de dados curado de pares (prompt, conclusão). O resultado é um modelo que absorveu padrões, terminologia e comportamento dos seus dados de treinamento em seus parâmetros. A proposta empresarial clássica: um modelo ajustado, sem sobrecarga de recuperação, inferência rápida.
Os custos ocultos: Uma execução de fine-tuning em um modelo de 7B parâmetros usando QLoRA em uma única A100 80GB leva de 4 a 12 horas e custa aproximadamente US$ 40 a US$ 120 no preço de GPU em nuvem no 1º trimestre de 2026. Para um modelo de 70B, multiplique por 8 a 10x. Isso é apenas a primeira execução. Toda vez que sua base de conhecimento muda — uma atualização de produto, uma revisão de política, uma nova regulamentação — você ou retreina ou aceita um comportamento desatualizado do modelo. A maioria dos domínios de conhecimento empresarial muda semanalmente ou diariamente.
A degradação da precisão é a outra armadilha. Um modelo ajustado pode alucinar com confiança informações de sua distribuição de treinamento que agora estão desatualizadas. A análise interna da Morgan Stanley do piloto de seu assistente de IA (divulgada em uma teleconferência de resultados de 2025) descobriu que modelos ajustados em dados financeiros exigiam retreinamento completo a cada 6-8 semanas para manter a precisão aceitável nas condições atuais do mercado, custando mais de US$ 200 mil por trimestre apenas em computação GPU.
RAG em Produção
Um pipeline RAG recupera trechos de documentos relevantes de um armazenamento de vetores no momento da inferência e os injeta na janela de contexto do modelo. O modelo raciocina sobre as evidências recuperadas, em vez de confiar apenas nos pesos treinados.
As principais vantagens são atualização e auditabilidade. Quando sua base de conhecimento muda, você atualiza o índice de vetores — uma operação que leva minutos para atualizações incrementais e horas para uma reindexação completa. Nenhum retreinamento de modelo é necessário. Você também obtém atribuição de fonte: cada resposta pode citar o trecho exato do documento no qual foi baseada, o que é extremamente importante para indústrias regulamentadas.
Os verdadeiros modos de falha: a qualidade da recuperação é o gargalo. Uma busca ingênua por similaridade de cosseno sobre embeddings recupera aproximadamente o conteúdo certo, mas perde cadeias de raciocínio complexas e de múltiplas etapas. Sistemas RAG de produção em empresas como Salesforce e ServiceNow migraram para recuperação híbrida (densa + esparsa BM25) mais reclassificação com um cross-encoder, adicionando ~80-120ms de latência por consulta, mas melhorando a precisão das respostas em 15-25% em benchmarks internos.
Comparação Direta: Custo, Latência, Precisão
Custo Total de Propriedade (Anual, Empresa de Médio Porte)
Assuma 10 milhões de consultas/ano, uma base de conhecimento de 50.000 documentos atualizada semanalmente e um modelo da classe GPT-4o.
- Abordagem de Fine-tuning: Fine-tuning inicial (US$ 800–US$ 2.000) + retreinamento semanal (US$ 400–US$ 1.200/semana) + inferência na hospedagem do modelo ajustado (US$ 3.000–US$ 6.000/mês) = US$ 85.000–US$ 140.000/ano
- Abordagem RAG: Hospedagem de banco de dados vetorial (Pinecone, Weaviate ou pgvector no RDS) (US$ 200–US$ 800/mês) + geração de embeddings para atualizações semanais (US$ 50–US$ 200/mês) + inferência do modelo base (US$ 4.000–US$ 8.000/mês) = US$ 52.000–US$ 108.000/ano
A RAG sai 20-40% mais barata nessa escala. A diferença aumenta drasticamente quando a frequência de atualização do conhecimento aumenta.
Latência
- Modelo Ajustado (sem recuperação): p95 de 200–400ms para uma resposta de 500 tokens em um endpoint GPU dedicado
- Pipeline RAG (embedding + busca vetorial + LLM): p95 de 400–900ms, dependendo da complexidade da recuperação e da reclassificação
- Modelo Ajustado + RAG (híbrido): p95 de 500–1.100ms
O fine-tuning vence em latência bruta por 200–500ms. Para a maioria das aplicações empresariais — copilotos internos, pesquisa de documentação, suporte ao cliente — essa diferença é imperceptível para os usuários. É importante para aplicações em tempo real, como interfaces de voz (onde menos de 500ms é um requisito rigoroso) ou sistemas de negociação onde milissegundos têm valor direto em dólares.
Precisão em Tarefas com uso Intensivo de Conhecimento
No benchmark FRAMES (um conjunto de avaliação de QA com vários documentos que se tornou o padrão de facto para avaliação RAG em 2025), um pipeline RAG bem ajustado usando GPT-4o alcançou 72-78% de precisão em perguntas empresariais de múltiplas etapas. Um GPT-4o ajustado no mesmo domínio obteve 61-67% — menor, porque o modelo ajustado estava respondendo com base em padrões memorizados, em vez de evidências recuperadas, e o conjunto de teste incluía perguntas sobre informações que mudaram após o corte de treinamento.
Para tarefas de classificação e extração com esquemas fixos, o fine-tuning vence: um modelo Llama 3.1 8B ajustado para extração de dados estruturados alcançou 94% de precisão em nível de campo contra 87% de um GPT-4o com prompt e contexto RAG, com 1/8 do custo de inferência.
Quando o Fine-tuning É Realmente a Escolha Certa
Existem quatro cenários onde o fine-tuning supera a RAG e as compensações são justificadas:
1. Vocabulário e Raciocínio de Domínio Especializado
Geração de laudos de imagem médica, classificação de cláusulas de contratos legais, verificação de design de chips — domínios onde a terminologia, os padrões de raciocínio e os formatos de saída são tão especializados que um modelo base requer centenas de tokens de explicação no contexto em cada consulta. O fine-tuning amortiza esse custo de contexto em todas as inferências. O modelo de sumarização clínica da Hippocratic AI e o sistema de análise de contratos da Harvey AI dependem do fine-tuning precisamente porque seus domínios exigem padrões de raciocínio que não podem ser elicitados de forma confiável apenas com prompting.
2. Requisitos Estritos de Latência (abaixo de 300ms)
Interfaces de voz, assistentes de codificação em tempo real integrados a IDEs (como o autocomplete do Cursor) e IA de borda em dispositivos onde a infraestrutura de recuperação não está disponível. Um modelo ajustado de 3B–7B rodando localmente é a única arquitetura viável quando você precisa de resposta abaixo de 300ms sem ida e volta à rede.
3. Formato e Estilo de Saída Consistentes
Se sua aplicação gera saídas em um formato altamente específico — JSON estruturado com um esquema proprietário, o estilo de escrita exato de uma marca, um idioma de programação específico — o fine-tuning fixa esse formato de forma mais confiável do que a engenharia de prompt. Ferramentas de conclusão de código estilo Copilot do GitHub e JetBrains usam fine-tuning por esse motivo.
4. Os Dados Não Podem Sair do Seu Ambiente
Algumas empresas não podem enviar documentos para um banco de dados vetorial externo ou API LLM devido a regulamentações de soberania de dados (requisitos de processamento de dados do Artigo 28 da Lei de IA da UE, HIPAA, FedRAMP). Um modelo ajustado totalmente local, sem dependência de recuperação, é arquiteturalmente mais simples do que uma pilha RAG local, embora esta última seja cada vez mais viável com clusters auto-hospedados de Weaviate ou Qdrant.
Quando a RAG É a Escolha Certa (Na Maioria das Vezes)
A RAG é o padrão correto para implantações empresariais quando:
- Sua base de conhecimento muda com mais frequência do que trimestralmente
- Você precisa de atribuição de fonte para conformidade ou confiança do usuário
- A distribuição de suas consultas é ampla (as perguntas abrangem muitos tópicos, não um domínio restrito)
- Você está trabalhando com uma base de conhecimento maior que 10.000 documentos, onde a memorização do fine-tuning se torna não confiável
- Você deseja testar A/B atualizações de modelo sem pipelines de retreinamento
O assistente Rovo da Atlassian, o Notion AI e o produto Fin da Intercom usam arquiteturas que priorizam RAG. O ponto em comum: suas bases de conhecimento (páginas do Confluence, documentos do Notion, tickets de suporte ao cliente) mudam continuamente, e a atualização é inegociável.
A Arquitetura Híbrida: Para Onde a Produção Está Caminhando
Os sistemas de IA empresarial mais capazes em 2026 usam fine-tuning e RAG juntos, mas de uma maneira específica. O LLM base é ajustado no formato da tarefa e no estilo de raciocínio — não no conhecimento factual. O conhecimento factual reside inteiramente na camada de recuperação. Essa separação de preocupações é às vezes chamada de "fine-tuning de formato + RAG de conhecimento."
O modelo Command R+ empresarial da Cohere é construído sobre esse princípio: o modelo foi ajustado por instruções para raciocínio específico de RAG (fundamentação de citações, síntese de evidências, cadeia de pensamento de múltiplas etapas) em vez de fatos de domínio. Os clientes conectam suas próprias bases de conhecimento. O resultado: melhor utilização da recuperação do que um modelo base genérico, sem o ônus do retreinamento do fine-tuning de conhecimento.
Framework de Decisão: Um Fluxograma Prático
Responda a estas perguntas em ordem:
- Sua base de conhecimento muda mais de uma vez por trimestre? Sim → RAG. Não → continue.
- Você precisa de atribuição de fonte ou trilhas de auditoria? Sim → RAG. Não → continue.
- A latência p95 é um requisito rigoroso abaixo de 300ms? Sim → Fine-tuning. Não → continue.
- Seu domínio é tão especializado que um modelo base exige prompts de sistema de 500+ tokens para se comportar corretamente? Sim → Fine-tuning (ou híbrido). Não → RAG.
- As regras de soberania de dados impedem chamadas de API externas? Sim → avalie RAG local vs. modelo local ajustado com base na complexidade da infraestrutura. Não → RAG.
Conclusões Acionáveis
- Comece com RAG. O investimento em infraestrutura é menor, a iteração é mais rápida e você sempre pode adicionar fine-tuning posteriormente para componentes específicos. O inverso — desfazer um investimento em fine-tuning — é caro.
- Se você fizer fine-tuning, ajuste para comportamento, não para fatos. Treine em padrões de raciocínio, formato de saída e estrutura de tarefa. Mantenha os fatos na camada de recuperação.
- Invista na qualidade da recuperação antes de escalar. A recuperação híbrida BM25 + densa com um reclassificador cross-encoder não é mais opcional para produção; é a linha de base. Uma RAG barata por similaridade de cosseno terá desempenho inferior a um modelo base com bom prompt.
- Meça a atualização separadamente da precisão. Um modelo pode obter uma boa pontuação em um benchmark estático enquanto fornece respostas desatualizadas em produção. Construa conjuntos de avaliação a partir de documentos adicionados após o corte de treinamento.
- Para borda/dispositivo: use modelos ajustados quantizados (GGUF Q4_K_M no llama.cpp) — a RAG é impraticável sem acesso confiável à rede.