OpenTelemetry se tornou o padrão de observabilidade — agora vem a parte difícil: usá-lo de fato
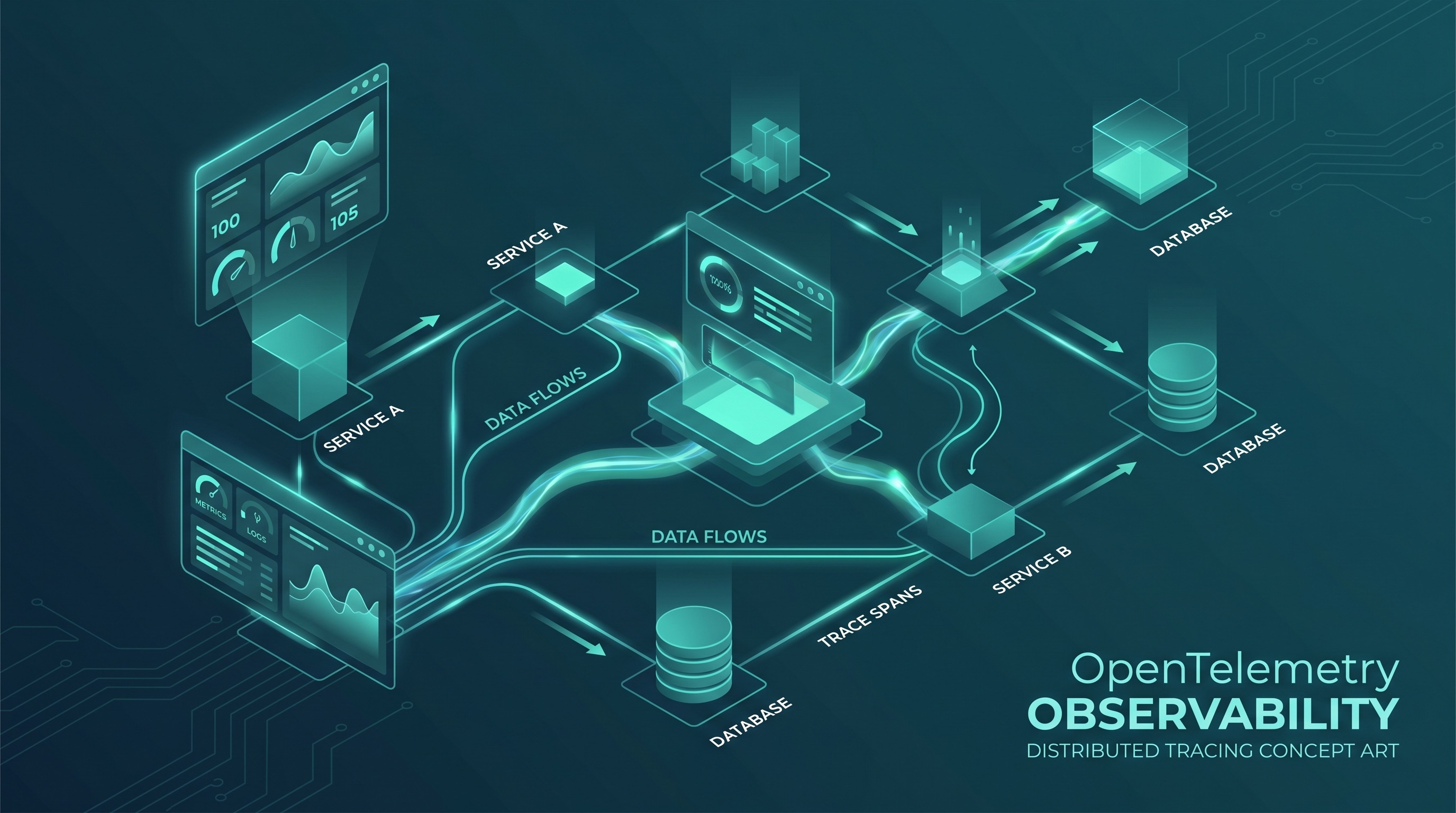
Três anos atrás, as equipes de engenharia que escolhiam uma stack de observabilidade enfrentavam uma decisão dolorosa: adotar Agents de instrumentação proprietários de um fornecedor e aceitar o lock-in, ou juntar ferramentas open-source díspares e arcar com a manutenção. O OpenTelemetry — projeto da CNCF que uniu OpenCensus e OpenTracing em 2019 — resolveu grande parte dessa decisão. Em 2026, tornou-se o padrão de fato para coleta de dados de telemetria em toda a indústria.
Datadog, Honeycomb, Grafana, New Relic, Dynatrace e Splunk aceitam dados do OpenTelemetry nativamente. Provedores de cloud como AWS, Google Cloud e Azure têm integração nativa com OpenTelemetry. Os SDKs para Python, Java, Go, JavaScript e .NET atingiram versões estáveis. O OpenTelemetry Collector — o componente de Pipeline que recebe, processa e exporta telemetria — está em produção em empresas que vão de pequenas startups a hyperscalers.
O OpenTelemetry venceu a guerra da instrumentação. O próximo problema é usá-lo bem.
O que o OpenTelemetry realmente padroniza
O OpenTelemetry define três sinais de telemetria: Traces (o caminho de uma requisição por serviços distribuídos), Metrics (medidas numéricas ao longo do tempo) e Logs (registros de eventos estruturados). O projeto fornece SDKs para gerar esses sinais, um formato de transmissão (OTLP — OpenTelemetry Protocol) para enviá-los, e o Collector para roteá-los para backends.
O que ele não padroniza é o que fazer com os dados depois que você os tem. As linguagens de consulta, modelos de alerta, ferramentas de dashboard e fluxos de análise são todos específicos de cada backend. Mudar do Datadog para o Grafana ainda exige reescrever dashboards e alertas — a camada de coleta de dados agora é portátil, mas a camada de análise não. Esse é o problema de "portabilidade de observabilidade" que a indústria ainda está resolvendo.
Onde as equipes travam
O modo de falha mais comum é tratar o OpenTelemetry como uma tarefa de checklist em vez de uma prática. As equipes instrumentam seus serviços, veem os Traces aparecendo no backend de observabilidade e declaram sucesso. Seis meses depois, quando ocorre um incidente em produção, descobrem que os Traces estão incompletos (alguns serviços não foram instrumentados), os Spans não têm atributos úteis (sem User IDs, sem Feature Flags, sem contexto de negócio), e a cardinalidade das Metrics ultrapassou os limites do backend.
A qualidade da instrumentação é a primeira lacuna. A Auto-instrumentation — onde o SDK gera automaticamente Spans para chamadas HTTP, consultas a banco de dados e operações de fila de mensagens — captura o esqueleto estrutural de uma requisição, mas nada sobre a lógica de negócio. Se uma chamada de API foi para um cliente premium ou de nível gratuito, qual Feature Flag estava ativa, qual era o total do carrinho: esses são atributos que exigem instrumentação manual para capturar. As equipes que mais obtêm valor do OpenTelemetry são aquelas que tratam os atributos dos Spans como produto de design deliberado, e não de geração automática.
A cardinalidade é a segunda lacuna. Cada combinação única de valores de atributo cria uma nova série temporal em um backend de Metrics. Uma Metric marcada com User ID, região, Feature Flag e código de status HTTP pode criar milhões de séries distintas — e muitos backends de observabilidade cobram por série temporal ou impõem limites rígidos. Equipes que instrumentam Metrics sem pensar cuidadosamente na cardinalidade acabam pagando contas de observabilidade inesperadamente altas ou atingindo limites de perda de dados exatamente quando mais precisam dos dados.
O Collector como um ativo estratégico
O OpenTelemetry Collector é sem dúvida o componente mais subutilizado do ecossistema. A maioria das equipes o implanta como um simples encaminhador — recebe OTLP dos serviços e exporta para o backend. O Pipeline de processamento do Collector pode fazer muito mais: filtrar dados de alta cardinalidade antes que cheguem ao backend, amostrar Traces com base em regras de negócio (amostrar 100% dos Traces de erro, 1% dos bem-sucedidos), enriquecer Spans com metadados do Kubernetes ou service discovery, e rotear diferentes sinais para diferentes backends.
Um pipeline do Collector bem configurado pode reduzir os custos de observabilidade em 60-80% sem perder sinais significativos, descartando agressivamente dados de baixo valor (Traces de health check, jobs de background rotineiros) enquanto preserva tudo que é relevante para debugging e análise de negócios. Equipes que tratam o Collector como infraestrutura para configurar com cuidado, em vez de implantar e esquecer, extraem muito mais valor do mesmo orçamento.
Convenções semânticas: o padrão subestimado
As convenções semânticas do OpenTelemetry — uma especificação de como nomear e estruturar atributos em Spans e Metrics — são a contribuição mais subestimada do projeto. Quando cada equipe nomeia seus atributos de Span de banco de dados de forma diferente, não é possível escrever dashboards ou alertas genéricos que funcionem entre serviços. Quando todos seguem as mesmas convenções (db.system, db.statement, http.method, http.status_code), as ferramentas conseguem raciocinar sobre a telemetria sem configuração específica por serviço.
A adoção das convenções semânticas ainda é incompleta na prática. As convenções estáveis cobrem HTTP, bancos de dados, sistemas de mensageria e RPC — os padrões de infraestrutura mais comuns. Muitos padrões específicos de aplicação não são cobertos ou ainda estão em status experimental. Equipes que constroem sobre o OpenTelemetry devem investir tempo em definir suas próprias convenções de atributos para contexto de nível de aplicação, seguindo os padrões de nomenclatura que o projeto estabelece, para obter os mesmos benefícios de composabilidade na camada de aplicação.
Como é o cenário ideal em 2026
As equipes que mais obtêm valor do OpenTelemetry em 2026 compartilham algumas características. Elas têm um time de plataforma ou um campeão de observabilidade que é dono da configuração do Collector e dos padrões de instrumentação. Elas definiram um conjunto de atributos de Span obrigatórios para novos serviços e os aplicam em code review. Elas fizeram uma análise explícita de cardinalidade em suas Metrics e tomaram decisões deliberadas sobre quais dimensões manter. Elas usam tail-based sampling para capturar Traces completos para erros e requisições lentas, enquanto amostram agressivamente o tráfego rotineiro.
Elas também tratam os dados de observabilidade como um produto, não como exaustão de infraestrutura. A pergunta não é 'estamos coletando dados?', mas 'o engenheiro de plantão consegue encontrar a causa raiz de um incidente de produção em menos de 10 minutos?'. Esse padrão gera decisões de instrumentação diferentes de 'o Collector está rodando?'
O OpenTelemetry resolveu o problema de coordenação mais difícil em observabilidade: fazer a indústria concordar com um formato comum de dados. A próxima camada de problemas — o que instrumentar, como configurar o Pipeline, o que construir em cima — são desafios de engenharia e organização que cada equipe precisa resolver por si mesma. A boa notícia é que a fundação agora está estável o suficiente para construir em cima.