SQLite é o banco de dados que a nuvem não esperava — e está ganhando de qualquer maneira
Existem aproximadamente 1 trilhão de implantações ativas de SQLite no mundo. Esse número, vindo da própria documentação do projeto SQLite, não é uma estimativa de marketing — é uma realidade arquitetural. Todo iPhone vem com SQLite. Todo dispositivo Android o executa. O Firefox usa para armazenar histórico, favoritos e cookies. O Chrome o utiliza como backend de banco de dados. Skype, Dropbox, iTunes, VLC e toda a Adobe Creative Suite o incorporam. A Biblioteca do Congresso dos EUA o recomenda como formato de arquivamento. SQLite é, por contagem de implantações, o motor de banco de dados mais usado que existe — e até recentemente, a maioria dos desenvolvedores pensava nele como algo que vem embutido em aplicativos mobile, não como infraestrutura séria.
Essa visão agora está obsoleta. Em 2026, o SQLite está rodando dentro da rede global de borda da Cloudflare, alimentando aplicações distribuídas através do fork libSQL do Turso e formando a base de uma arquitetura de aplicação local-first que está atraindo atenção séria da engenharia. O banco de dados que passou trinta anos sendo chamado de "não para produção" está redefinindo silenciosamente o que produção significa.
O que SQLite realmente é
SQLite é uma biblioteca C — cerca de 155.000 linhas — que implementa um motor de banco de dados SQL completo em um único arquivo, sem dependências externas, sem processo servidor e sem configuração. Um banco de dados é apenas um arquivo no disco. Abri-lo não requer string de conexão, handshake de autenticação ou daemon em execução para conectar. Você vincula a biblioteca, abre o arquivo e executa SQL. Essa é a configuração inteira.
Apesar de sua simplicidade, SQLite é totalmente compatível com ACID. As escritas são atômicas; leituras concorrentes são suportadas através do modo WAL (Write-Ahead Log); o formato on-disk é estável e totalmente compatível com versões anteriores desde 2004. Ele suporta SQL-92 completo com a maior parte de SQL:1999, incluindo funções de janela, CTEs e operadores JSON adicionados em versões mais recentes. O projeto é mantido por uma pequena equipe sob dedicação de domínio público — sem licença, sem direitos autorais, sem acordos de contribuição.
Richard Hipp começou o projeto em 2000 para o programa de destroyers de mísseis guiados da Marinha dos EUA, onde a ausência de um administrador de banco de dados era uma restrição de projeto, não um descuido. Essa origem define tudo sobre o SQLite: foi construído para ambientes onde você não pode ter um servidor, um DBA ou conectividade de rede. Essas restrições, descobre-se, descrevem o ambiente de computação de borda quase perfeitamente.
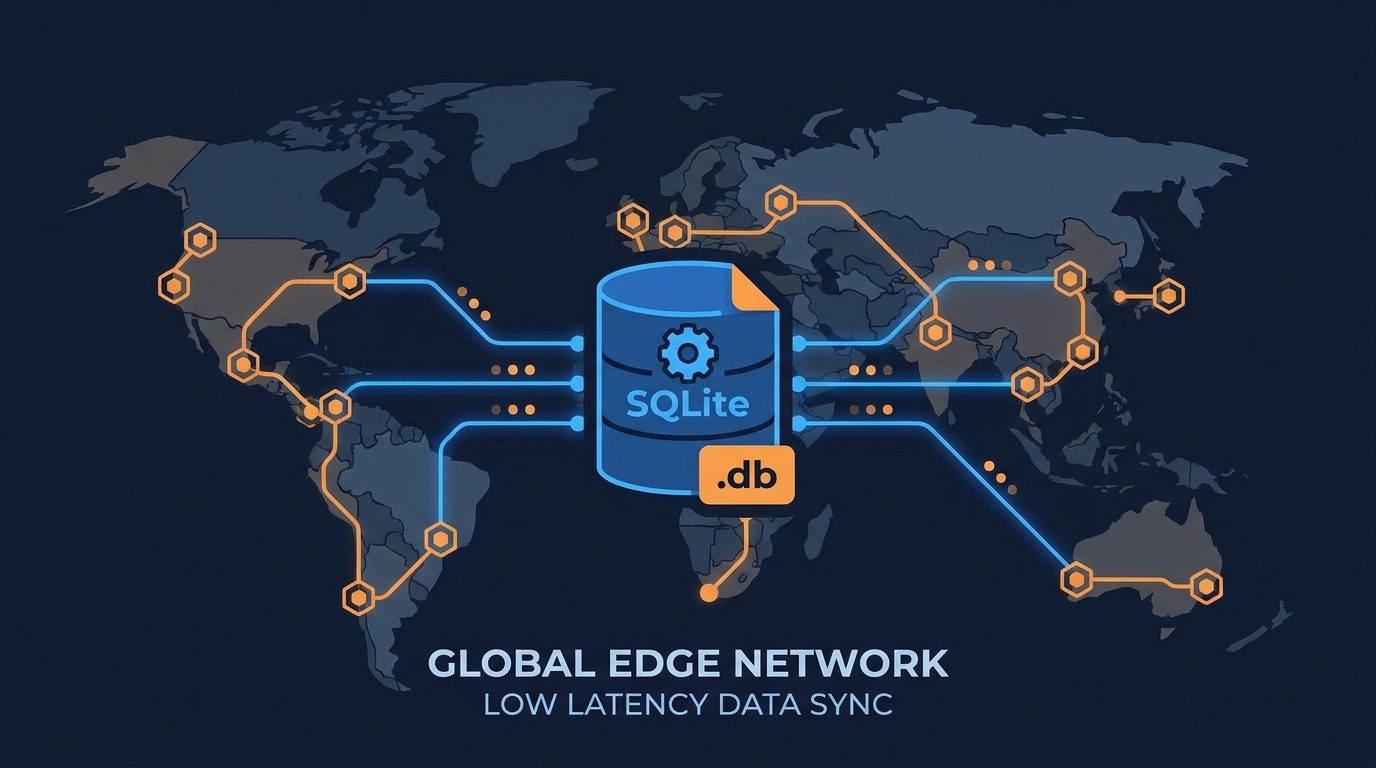
SQLite na borda: Cloudflare D1, Turso e LiteFS
Cloudflare D1, lançado em disponibilidade geral em 2023 e substancialmente expandido ao longo de 2024–2025, é o SQLite rodando dentro de Cloudflare Workers em mais de 300 locais de borda no mundo todo. Quando um Worker executa uma consulta D1, ele está executando contra um arquivo SQLite co-localizado no nó de borda mais próximo do usuário. As leituras são submilissegundo. O banco de dados pode escalar para 10 GB por banco sem provisionamento — você cria um banco de dados D1 em um comando CLI e ele fica imediatamente disponível globalmente.
D1 resolve o problema de escrita através de um modelo primário-réplica: as escritas vão para uma localização primária e são replicadas assincronamente para todos os nós de borda. Para cargas de trabalho com muita leitura — o que descreve a maioria das aplicações web — a vantagem de latência sobre uma instância PostgreSQL de região única é substancial. A Cloudflare relata que D1 serve mais de 50 bilhões de linhas lidas por mês em sua base de clientes no início de 2026.
Turso, construído sobre libSQL — um fork open-source do SQLite mantido pela ChiselStrike — adota uma abordagem arquitetural diferente. O libSQL estende o SQLite com replicação nativa, modo servidor e suporte a API HTTP, mantendo-se compatível com fios com arquivos SQLite padrão. O Turso fornece réplicas embarcadas: sua aplicação executa uma réplica SQLite local que se mantém sincronizada com um banco de dados central, oferecendo leituras locais com latência zero e consistência eventual nas escritas. O modelo é explicitamente projetado para runtimes de borda e funções serverless onde o custo de latência de uma chamada de banco de dados remota é proibitivo.
LiteFS, desenvolvido por Ben Johnson e agora mantido sob o guarda-chuva da Fly.io, adota uma abordagem baseada em FUSE para replicação do SQLite. Ele intercepta escritas no sistema de arquivos a nível de SO e replica o write-ahead log do SQLite para outros nós através de uma camada de consenso. As aplicações não precisam de alterações de código — o LiteFS se posiciona entre a aplicação e o sistema de arquivos, sincronizando transparentemente bancos de dados SQLite em um cluster Fly.io. Fly.io Volumes, a camada de armazenamento persistente para aplicações Fly, combinado com LiteFS dá aos desenvolvedores uma configuração SQLite distribuída com failover automático e replicação entre múltiplas regiões.
SQLite-over-HTTP e os novos padrões de acesso
Um dos desenvolvimentos mais interessantes no ecossistema SQLite é o surgimento de camadas de acesso baseadas em HTTP que fazem com que ele se comporte mais como um banco de dados cliente-servidor tradicional sem abrir mão de suas vantagens embarcadas. O modo servidor do libSQL expõe uma API WebSocket e HTTP à qual clientes podem se conectar remotamente — significando que um banco de dados SQLite rodando em um servidor pode ser consultado a partir de um navegador, um aplicativo mobile ou uma função serverless usando semântica HTTP padrão.
Isso é importante porque desbloqueia o SQLite para ambientes onde incorporar a biblioteca diretamente não é possível. Uma aplicação Next.js implantada na Vercel não pode empacotar uma biblioteca SQLite nativa — mas pode fazer requisições HTTP para um banco de dados Turso e receber resultados de consultas SQL como JSON. A experiência do desenvolvedor é quase idêntica a consultar o Postgres através de um pool de conexões, mas o motor subjacente é SQLite, com toda a simplicidade operacional que isso implica.
Bun, o runtime JavaScript que vem ganhando tração como uma alternativa mais rápida ao Node.js, vem com suporte nativo a SQLite através do seu módulo bun:sqlite — sem necessidade de npm install, sem compilação de módulo nativo, sem node-gyp. const db = new Database("mydb.sqlite"); é a configuração inteira. Os números de desempenho que Bun cita para sua implementação SQLite — mais de 4 milhões de leituras por segundo em um laptop — refletem o quão rápido um banco de dados com zero overhead de rede pode ser quando roda no mesmo processo que o código da sua aplicação.
Arquitetura local-first e a ascensão dos CRDTs
O movimento local-first no desenvolvimento de aplicações web é construído sobre uma afirmação específica: que a arquitetura correta para a maioria das aplicações é aquela onde o banco de dados vive no cliente, as leituras são instantâneas porque acessam armazenamento local, e a sincronização com um servidor ocorre em segundo plano. A experiência do usuário é mais rápida, a capacidade offline é nativa, e o servidor se torna um retransmissor de sincronização, em vez de um gargalo de consulta.
SQLite é a escolha natural para essa arquitetura porque roda em todos os lugares — no navegador via WebAssembly (wa-sqlite, sql.js), em aplicações Electron nativamente, em mobile via SQLite embutido da plataforma, e em nós de borda através de D1 ou Turso. As mesmas consultas SQL funcionam em todos esses ambientes contra arquivos que são fundamentalmente compatíveis entre si.
O problema difícil na arquitetura local-first é a resolução de conflitos: se dois clientes escrevem em uma réplica SQLite local enquanto estão offline, como mesclar essas escritas quando eles reconectam? É aqui que os CRDTs (Conflict-free Replicated Data Types) entram em cena. cr-sqlite, uma extensão SQLite desenvolvida por Matt Wonlaw na Vlcn.io, implementa semântica de CRDT diretamente no SQLite instrumentando tabelas SQL padrão com um relógio de Lamport e uma função de mesclagem. Dois bancos de dados cr-sqlite podem ser mesclados deterministicamente sem uma autoridade central. Qualquer conflito em nível de linha é resolvido pelas regras de mesclagem do CRDT, não por um servidor decidindo qual escrita vence.
Essa combinação — SQLite para armazenamento, CRDTs para semântica de mesclagem, um retransmissor de sincronização para conectividade — é a arquitetura por trás de ferramentas como ElectricSQL, Replicache e Zero (da equipe Rocicorp que construiu o Replicache). Não é mais puramente experimental: Linear, a ferramenta de gerenciamento de projetos, usa uma arquitetura local-first baseada em SQLite para seu aplicativo desktop e atribui sua sensação de fluidez especificamente ao fato de que cada interação atinge um banco de dados local em vez de uma API remota.
Ferramentas para desenvolvedores em 2026
O ecossistema de ORMs e ferramentas alcançou o papel expandido do SQLite. O Drizzle ORM, um dos ORMs TypeScript que mais cresce, trata SQLite como um alvo de primeira classe ao lado de PostgreSQL e MySQL — com adaptadores específicos para better-sqlite3, SQLite nativo do Bun, libSQL, D1 e Turso. A inferência de tipos do Drizzle significa que seu esquema SQLite impulsiona seus tipos TypeScript com zero overhead em tempo de execução.
O Prisma adicionou suporte a D1 em 2024 com seu modelo de adaptadores de driver, permitindo que o motor de consulta do Prisma execute contra o Cloudflare D1 através da API HTTP do D1. A definição do esquema Prisma permanece idêntica quer você esteja mirando Postgres ou D1; apenas a inicialização do cliente muda. better-sqlite3, a ligação SQLite para Node.js de Joshua Wise, continua sendo a escolha para acesso SQLite síncrono e de alto desempenho em Node.js no lado do servidor — seu design de API síncrona é uma escolha deliberada, combinando com a própria natureza síncrona do SQLite e evitando o overhead assíncrono que aflige a maioria dos drivers de banco de dados.
Onde SQLite realmente fica aquém
O modelo de escritor único do SQLite é sua restrição arquitetural mais significativa. Apenas uma transação de escrita pode ser executada por vez — mesmo no modo WAL, que permite leituras concorrentes junto com um único escritor, você não pode ter dois processos escrevendo no mesmo banco de dados SQLite simultaneamente sem serialização. Para aplicações com alta taxa de escrita concorrente — um placar recebendo milhares de atualizações de pontuação por segundo, um sistema de mensagens com escritas simultâneas de milhares de clientes conectados — o modelo de escrita do SQLite é uma parede intransponível.
O modo WAL ajuda significativamente para cargas de trabalho com muita leitura e escritas ocasionais: leitores nunca bloqueiam escritores e escritores nunca bloqueiam leitores. Mas o WAL não muda a restrição fundamental de escritor único. Se seu gargalo é concorrência de escrita, você precisa de um banco de dados com um gerenciador de bloqueios projetado para isso — PostgreSQL, MySQL ou um sistema distribuído como CockroachDB.
Também não há replicação nativa. O SQLite padrão não tem conceito de primário/réplica, nem envio de WAL, nem slots de replicação lógica. Toda solução de replicação no ecossistema — LiteFS, réplicas embarcadas do Turso, cr-sqlite — é uma camada construída sobre o SQLite por terceiros. Isso significa que as configurações de replicação carregam mais complexidade operacional do que parecem: você está gerenciando dois sistemas (SQLite mais a camada de replicação) em vez de um. E as garantias de consistência variam: as réplicas embarcadas do Turso são eventualmente consistentes, não fortemente consistentes — uma escrita em uma réplica pode não ser imediatamente visível em outra.
O tamanho do arquivo do banco de dados também se torna uma consideração em escala. SQLite lida com bancos de dados de dezenas de gigabytes rotineiramente e foi testado até centenas de gigabytes, mas nessa escala, você perde parte da simplicidade operacional que torna o SQLite atraente. Mover um arquivo SQLite de 50 GB para fins de backup é uma proposição diferente de replicá-lo através de um fluxo baseado em log.
Quando escolher SQLite, e quando não
SQLite é a escolha certa quando sua proporção leitura/escrita é alta, quando você quer zero overhead operacional, quando está construindo para a borda ou para arquiteturas local-first, ou quando está enviando uma ferramenta de desenvolvedor, CLI ou aplicação embarcada onde um servidor de banco de dados seria absurdo. D1 e Turso tornaram viável para aplicações web de produção com usuários globais, desde que essas aplicações sejam pesadas em leitura e possam tolerar consistência eventual nas escritas.
PostgreSQL continua sendo a escolha certa quando você precisa de forte concorrência de escrita, bloqueio em nível de linha, topologias de replicação complexas ou o ecossistema profundo de extensões (PostGIS, pgvector, TimescaleDB) que o Postgres construiu ao longo de trinta anos. MySQL e MariaDB ocupam território similar. Um banco de dados distribuído como CockroachDB ou PlanetScale é justificado quando você precisa de escalabilidade horizontal de escrita com fortes garantias de consistência entre regiões — um caso de uso que o SQLite nunca foi projetado para abordar.
A questão mais interessante para 2026 não é "SQLite vs. Postgres", mas "onde cada um pertence no mesmo sistema?" Muitas arquiteturas de produção agora usam ambos: SQLite na borda para dados específicos do usuário com baixa escrita (estado de sessão, preferências, feeds por usuário) e Postgres no centro para dados compartilhados com alta escrita (transações, inventário, mensagens). O banco de dados que a nuvem não esperava encontrou seu lugar na stack — não substituindo o que veio antes, mas lidando com os casos onde montar um cluster Postgres sempre foi a resposta errada.