Pacote PyPI envenenado invadiu a startup de treinamento de IA Mercor — e expôs 4 TB de dados de prestadores ao grupo Lapsus$
Em 31 de março de 2026, a Mercor — uma startup de US$ 10 bilhões que fornece serviços de rotulagem de dados, anotação e gestão de prestadores para OpenAI, Anthropic, Meta e Google — confirmou uma violação que especialistas em segurança estão chamando de um dos ataques à cadeia de suprimentos mais impactantes já direcionados à indústria de IA. Cerca de 4 TB de dados foram exfiltrados: 939 GB de código-fonte da plataforma, 211 GB de registros de banco de dados de usuários e aproximadamente 3 TB de conteúdo de buckets de armazenamento, incluindo cópias de passaportes de prestadores, números de Seguro Social, documentos de verificação de identidade e gravações em vídeo de entrevistas técnicas. O grupo que reivindicou a autoria é o Lapsus$, que listou os dados roubados para leilão em seu marketplace na dark web. Cinco ações coletivas já foram ajuizadas contra a Mercor por prestadores afetados.
A cadeia do ataque: três saltos do escâner até a produção
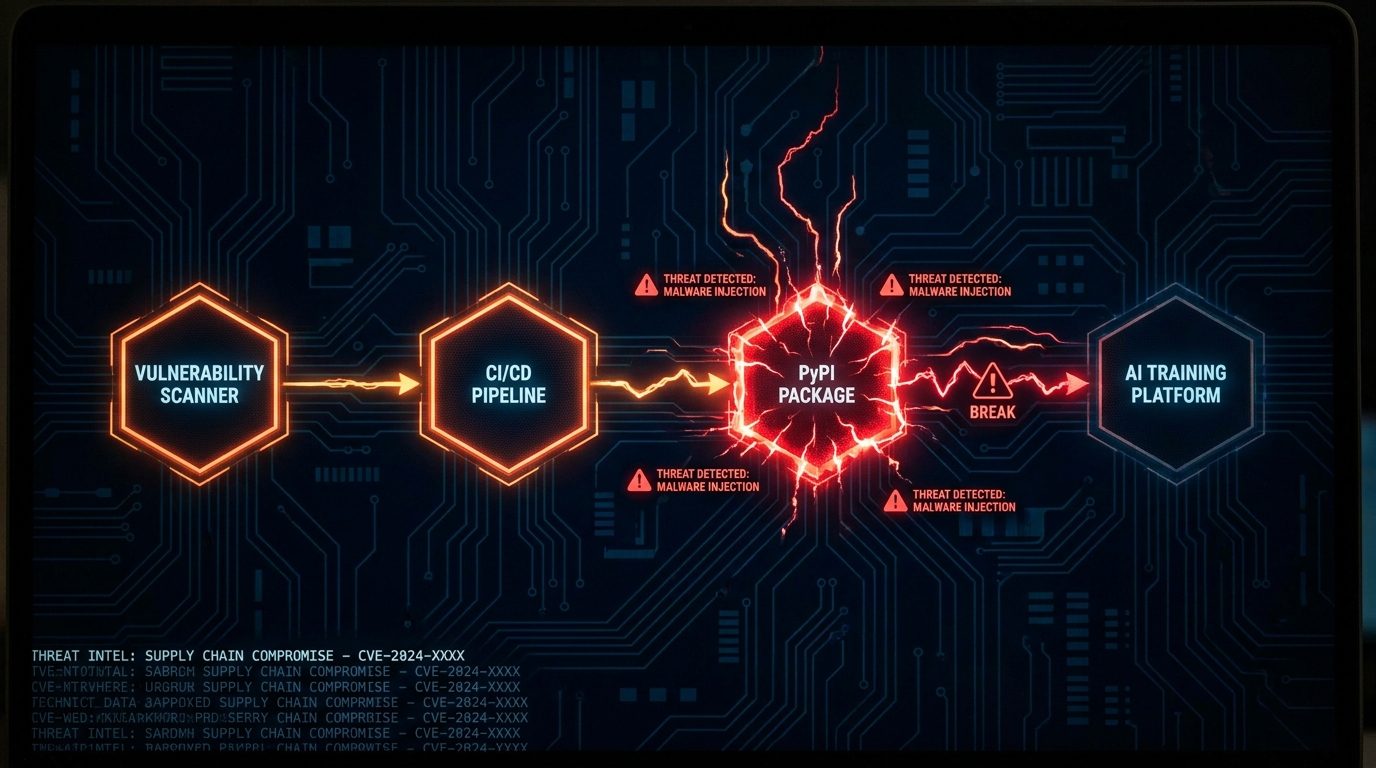
O que torna essa violação tecnicamente distinta é o caminho do ataque. Não foi uma intrusão direta nos sistemas da Mercor. Foi um ataque à cadeia de suprimentos em três estágios que percorreu o ecossistema de ferramentas open source antes de atingir qualquer ambiente de produção.
Salto 1 — 19 de março: Trivy é comprometido. O Trivy é um escâner de vulnerabilidades open source amplamente utilizado, mantido pela Aqua Security e integrado a pipelines de CI/CD em milhares de organizações. O grupo de atacantes, operando sob o nome TeamPCP, obteve acesso de escrita aos artefatos de release do Trivy. O vetor inicial exato para o Trivy não foi divulgado publicamente, mas o resultado foi que o TeamPCP tinha a capacidade de influenciar o que o Trivy executava durante suas varreduras.
Salto 2: Extração de credenciais de CI/CD do LiteLLM. O LiteLLM — uma biblioteca Python open source popular que fornece um gateway API unificado para chamar diferentes provedores de modelos de linguagem grandes — usava o Trivy como parte de seu pipeline automatizado de CI/CD para escanear contêineres e dependências em busca de vulnerabilidades conhecidas. Criticamente, a configuração de CI/CD do LiteLLM não fixava o Trivy a um hash de versão específico. Ele puxava o Trivy sem version locking, o que significava que, quando o Trivy comprometido era executado dentro do ambiente de build do LiteLLm, ele tinha acesso aos segredos do pipeline: credenciais de publicação no PyPI, tokens de repositório e variáveis de ambiente. O TeamPCP extraiu essas credenciais por meio do escâner comprometido durante uma execução de build de rotina.
Salto 3 — 27 de março: Versões maliciosas do LiteLLM no PyPI. Munido das credenciais de publicação no PyPI do LiteLLM, o TeamPCP publicou duas releases maliciosas: litellm==1.82.7 e litellm==1.82.8. Os pacotes eram funcionalmente idênticos às releases legítimas em seu comportamento superficial — passavam em testes básicos de importação e podiam rotear chamadas de API de LLM normalmente. O payload injetado era executado na importação ou no primeiro uso, estabelecendo conectividade de saída e exfiltrava variáveis de ambiente, chaves de API e caminhos do sistema de arquivos acessíveis ao processo em execução. Qualquer organização que puxasse essas versões para um ambiente de produção — via pip install litellm sem version pinning, ou via automação de atualização de dependências — executava código controlado pelos atacantes.
A Mercor foi uma dessas organizações. Considerando que o LiteLLM é usado em todo o ecossistema de desenvolvimento de IA como infraestrutura para construir aplicações que chamam GPT-4, Claude, Gemini e outros modelos, a janela de exposição foi ampla. A plataforma da Mercor, que gerencia fluxos de trabalho de prestadores, armazena documentos de identidade de prestadores e lida com dados de treinamento proprietários para os principais laboratórios de IA, era um alvo de alto valor dentro dessa janela.
O que foi roubado
Os dados exfiltrados da Mercor se dividem em três categorias, cada uma com perfis de risco distintos:
- 939 GB de código-fonte da plataforma. Isso inclui o sistema de gerenciamento de prestadores da Mercor, ferramentas de avaliação e as interfaces pelas quais os prestadores interagem com tarefas de treinamento de IA. Para os clientes da Mercor — OpenAI, Anthropic, Meta, Google — a exposição desse código potencialmente revela como seus pipelines de treinamento são estruturados na camada de interface com prestadores, quais tipos de tarefas são roteadas pela Mercor e quais mecanismos de controle de qualidade estão em vigor.
- 211 GB de registros de banco de dados de usuários. Isso inclui perfis de prestadores, metadados de contas, registros de pagamento e correspondência interna. O esquema exato não foi confirmado, mas, dado os requisitos de conformidade da Mercor para onboarding de prestadores, o banco de dados quase certamente inclui informações pessoalmente identificáveis para dezenas de milhares de prestadores.
- Aproximadamente 3 TB de conteúdo de buckets de armazenamento. Esta é a categoria mais sensível para prestadores individuais. Os buckets de armazenamento continham gravações em vídeo de entrevistas técnicas usadas para verificação de identidade e triagem de competência, digitalizações de documentos emitidos pelo governo, incluindo passaportes e carteiras de identidade nacionais, números de Seguro Social coletados durante o onboarding de prestadores nos EUA e documentos de verificação de identidade enviados para atender requisitos de KYC. A combinação de vídeo biométrico, documento de identidade e SSN representa um pacote de identidade completo para os prestadores afetados — suficiente para roubo de identidade, fraude de identidade sintética e engenharia social direcionada.
Por que as cadeias de suprimentos de treinamento de IA são um alvo excepcionalmente sensível
Uma violação de uma plataforma padrão de gerenciamento de prestadores SaaS seria grave principalmente pela exposição de dados pessoais. A violação da Mercor é categoricamente diferente por causa do que os prestadores que trabalham pela Mercor realmente lidam.
Os prestadores de IA no nível da base de clientes da Mercor não estão fazendo entrada de dados genérica. Eles estão realizando tarefas que tocam nos aspectos mais proprietários e competitivamente sensíveis do desenvolvimento de IA: avaliar saídas de modelos em benchmarks de capacidade que não foram lançados publicamente, anotar casos de borda que revelam onde um modelo atualmente falha, classificar respostas de acordo com critérios que codificam a metodologia de treinamento RLHF de uma empresa e testar filtros de segurança de maneiras que expõem o que o modelo pode e não pode fazer. As instruções, rubricas e especificações de tarefas que os prestadores recebem são o núcleo intelectual de como esses laboratórios treinam e alinham seus modelos.
O código-fonte da Mercor — que inclui as interfaces e ferramentas através das quais essas tarefas são entregues — poderia expor essas metodologias mesmo que os dados individuais da tarefa não estivessem no conjunto exfiltrado. Para um adversário construindo um modelo concorrente, ou para um ator estatal tentando entender os limites de segurança e as técnicas de treinamento de sistemas de IA de fronteira, isso representa acesso a informações que não podem ser reconstruídas a partir de pesquisa pública.
Resposta a jusante
A resposta dos clientes da Mercor foi comedida, mas significativa. A Meta pausou indefinidamente todo o trabalho de dados roteado pela Mercor em 2 de abril, dois dias após a violação ser confirmada, citando incerteza sobre a integridade do ambiente de prestadores e a potencial exposição de especificações de tarefas. OpenAI e Anthropic emitiram comunicados confirmando que estão auditando sua exposição — especificamente revisando se quaisquer dados de treinamento proprietários, rubricas de anotação ou frameworks de avaliação estavam acessíveis aos prestadores através da plataforma agora comprometida da Mercor no momento da violação.
Nem OpenAI nem Anthropic confirmaram se materiais de treinamento proprietários estavam dentro dos dados exfiltrados. O dump de 939 GB de código-fonte é o vetor mais provável para exposição indireta: se o código-fonte da plataforma da Mercor inclui modelos de tarefas incorporados, critérios de avaliação ou amostras de saída de modelo usados para treinar a qualidade dos prestadores, esses agora estariam na posse do Lapsus$.
O Lapsus$ listou o conjunto completo de 4 TB de dados para leilão em seu mercado da dark web, com o que fontes descrevem como um preço pedido de sete dígitos. O grupo tem um histórico documentado de concretizar vendas de dados — mais notavelmente com dados roubados da Nvidia, Samsung e Microsoft em 2022 — o que dá credibilidade à listagem do leilão além de uma típica ameaça de extorsão.
Cinco ações coletivas foram ajuizadas no tribunal federal dos EUA por prestadores afetados, alegando práticas negligentes de segurança de dados, falha na implementação de controles adequados de cadeia de suprimentos e notificação inadequada após a violação. As ações nomeiam especificamente a Mercor; nenhuma ainda nomeou as empresas de IA cujos programas de prestadores eram hospedados na plataforma.
O que os desenvolvedores devem fazer
Se sua base de código usa o LiteLLM, as etapas imediatas são específicas:
- Verifique sua versão instalada. Execute
pip show litellmou inspecione seurequirements.txt,pyproject.tomlou lockfile. Se você tiverlitellm==1.82.7oulitellm==1.82.8em qualquer lugar do seu gráfico de dependências — incluindo dependências transitivas — trate o ambiente como comprometido. Rode todos os segredos acessíveis a esse processo: chaves de API, credenciais de banco de dados, tokens de provedor de nuvem e quaisquer variáveis de ambiente. - Audite sua estratégia de pinning de dependências no PyPI. Qualquer dependência puxada com um intervalo de versão (
litellm>=1.82) ou sem restrição de versão (litellm) estava vulnerável a essa classe de ataque. Fixe em versões exatas e use um lockfile (poetry.lockdo Poetry ourequirements.txtgerado pelopip-compile) que inclua hashes. A flag de pinning de hash--require-hashesno pip torna impossível instalar um pacote cujo conteúdo não corresponda ao hash registrado, mesmo que um atacante substitua uma versão no PyPI. - Revise o pinning de versão de ferramentas do seu CI/CD. A violação do LiteLLM se originou porque o Trivy não foi fixado a uma versão específica no pipeline de build do LiteLLM. Todas as ferramentas no seu pipeline de CI/CD — escâneres, linters, ferramentas de build, executores de teste — devem ser fixadas a uma versão específica e idealmente a um hash de conteúdo. O GitHub Actions permite fixar actions a um commit SHA completo, em vez de uma tag, o que previne ataques de tag mutable. Para ferramentas baseadas em contêiner como o Trivy, fixe no image digest (
aquasec/trivy@sha256:...), não na tag (aquasec/trivy:latest). - Audite quais segredos estão acessíveis no seu ambiente de build. Credenciais de publicação no PyPI nunca devem estar disponíveis como variáveis de ambiente no mesmo passo do pipeline que executa varredura de dependências ou testes. Use jobs de pipeline separados com escopos de credenciais distintos e aplique princípios de privilégio mínimo a quais segredos cada passo pode acessar.
O padrão: ataques à cadeia de suprimentos contra ferramentas de desenvolvedor
O ataque ao LiteLLM é o mais recente em uma sequência de ataques à cadeia de suprimentos que progressivamente visaram camadas mais profundas da pilha de ferramentas de desenvolvedor:
- SolarWinds (dezembro de 2020): Atores estatais (APT29/Cozy Bear) comprometeram o sistema de build da SolarWinds, injetando um backdoor na plataforma Orion distribuída a cerca de 18.000 organizações, incluindo agências federais dos EUA. O vetor de ataque foi o próprio pipeline de build.
- Codecov (abril de 2021): Atacantes modificaram o script bash uploader do Codecov hospedado em sua própria infraestrutura. Qualquer pipeline de CI/CD que executasse o script — um padrão comum para relatórios de cobertura de código — enviava variáveis de ambiente, incluindo segredos, para servidores controlados pelos atacantes.
- xz Utils (março de 2024): Uma sofisticada campanha de engenharia social de vários anos resultou na incorporação de um backdoor na biblioteca de compressão xz, visando a autenticação do servidor SSH em sistemas Linux. O atacante passou dois anos construindo confiança como um contribuidor legítimo antes de inserir o código malicioso.
- LiteLLM via Trivy (março de 2026): Um escâner de vulnerabilidades usado sem version pinning tornou-se o ponto de entrada para roubo de credenciais, o que então permitiu que um pacote malicioso fosse publicado no PyPI sob o nome de uma biblioteca confiável.
O fio condutor é consistente: os atacantes não estão rompendo defesas de aplicações endurecidas. Eles estão explorando as relações de confiança entre ferramentas nas quais os desenvolvedores dependem para construir, testar e implantar software. À medida que as ferramentas de desenvolvimento de IA se tornam mais interconectadas — com bibliotecas como o LiteLLM servindo como infraestrutura crítica para rotear chamadas a modelos de fronteira — o raio de explosão de uma única dependência comprometida cresce proporcionalmente. A violação da Mercor não é um outlier. É uma ilustração do que os próximos anos de ataques à cadeia de suprimentos contra a indústria de IA parecerão.
Originally reported by Security Boulevard. Read the original article for additional details.
View original source